
Save your Time with the Best Ways to Label Tools

Data labeling is a crucial step in the development of machine learning models. It involves the process of annotating data with labels that can be used to train and test machine learning algorithms. However, choosing the right labeling method can be a challenging task, as it depends on the specific use case and the type of data being labeled. In this article, I’ll explore the best ways to label tools for data labeling in machine learning and will delve into different methods, discussing their strengths and weaknesses and providing examples of their use in real-world applications. By the end of this article, you will have a better understanding of the different ways to label tools and be better equipped to choose the right labeling method for your specific use case. How Do Neural Networks work? | Learn Artificial Intelligence in Less than 10 Minutes Best Ways to Label Tools 1. Bounding Boxes Bounding boxes are a popular labeling method for object detection tasks, where the goal is to identify and locate specific objects within an image or video. A bounding box is a rectangular box that is drawn around an object in an image or video frame. The box is labeled with the class of the object it contains. For example, in an image of a street scene, a bounding box might be drawn around a car, a pedestrian, or a building. The strengths of bounding boxes as a labeling method are their simplicity and efficiency. Bounding boxes are easy to draw and can be labeled quickly and accurately. They are also easy to use as input for machine learning algorithms, as they provide a clear and consistent representation of the objects in the data. However, bounding boxes also have some weaknesses. They are not well-suited for labeling irregularly shaped objects or objects with complex structures. They also do not provide information about the precise location of the object within the box, which can be a limitation for some applications. 2. Polygons Polygons are a more flexible labeling method than bounding boxes, as they can be used to label irregularly shaped objects or objects with holes in them. A polygon is a closed shape that is drawn around an object in an image or video frame. The shape is labeled with the class of the object it contains. For example, in an image of a cell, a polygon might be drawn around the nucleus or the cytoplasm. The strengths of polygons as a labeling method are their flexibility and accuracy. Polygons can be used to label a wide range of objects, regardless of their shape or structure. They also provide more precise information about the location of the object within the shape, which can be useful for some applications. However, polygons also have some weaknesses. They can be more time-consuming to draw and label than bounding boxes, especially for complex shapes. They also require more storage space and computational resources, as they contain more information than bounding boxes. 3. 2-D and 3-D Points 2-D and 3-D points are labeling method that is used to identify specific points or landmarks within an image or video frame. The points are labeled with the class of the object they belong to. For example, in an image of a face, points might be labeled for the eyes, nose, and mouth. The strengths of 2-D and 3-D points as a labeling method are their precision and accuracy. They provide a detailed and consistent representation of the objects in the data, which can be useful for applications that require fine-grained analysis or tracking. However, 2-D and 3-D points also have some weaknesses. They can be more time-consuming to label than bounding boxes or polygons, especially for large datasets. They also require more storage space and computational resources, as they contain more information than other labeling methods. 4. Semantic Segmentation Semantic segmentation is a labeling method that is used to identify and label every pixel in an image or video frame with the class of the object it belongs to. For example, in an image of a street scene, every pixel might be labeled with the class of the object it belongs to, such as road, sidewalk, building, or car. The strengths of semantic segmentation as a labeling method are its accuracy and granularity. It provides a detailed and comprehensive representation of the objects in the data, which can be useful for applications that require precise analysis or segmentation. Choosing the Right Labeling Method Choosing the right labeling method depends on several factors, including the type of data, the specific use case, and the available tools and resources. Some labeling methods may be more suitable for certain types of data or applications than others. For example, bounding boxes may be more suitable for object detection tasks, while semantic segmentation may be more suitable for image segmentation tasks. When choosing a labeling method, it is important to consider the trade-offs between accuracy, efficiency, and complexity. It is recommended to experiment with different labeling methods and evaluate their performance on a small subset of the data before scaling up to larger datasets. This can help identify the strengths and weaknesses of each method and inform the decision of which method to use for the specific use case. Top 15 Data Labeling Platforms 1. Label Your Data This platform offers an intuitive interface for data annotation, making it easy even for those new to the world of data labeling. It is versatile and supports various types of data such as images, text, and videos. 2. People for AI A community-driven platform, People for AI harnesses the power of its user base to provide labeled datasets. The collective intelligence ensures diverse and accurate labeling. 3. Suntech AI Suntech AI combines AI-driven mechanisms with human intelligence to provide high-quality labeled data. They pride themselves on speed and scalability, making them suitable for larger projects. 4. Cloud Factory Specializing in manual data labeling, Cloud Factory offers a workforce trained in handling intricate
Choosing the Best Lidar Company in 2023

We’ve seen the ascendance of Lidar (Light Detection and Ranging) technology, revolutionizing our perception of the world. Its role in the rapidly growing fields of autonomous vehicles, advanced robotics, and 3D mapping cannot be overlooked. But with so many companies entering this space, identifying the best LiDAR company can be challenging. As 2023 unfolds, the ecosystem is rife with Lidar companies, each heralding its unique edge. But which among them truly leads the pack? In this post, I’ll guide you through the intricacies of selecting the best Lidar company this year. For the tech aficionados hungry for the latest in Computer Vision, this is your essential compass. Let’s navigate the Lidar landscape together!AI Prompt Engineering | Easy AI Job What is LiDAR? LiDAR is a remote sensing technology that uses lasers to map the environment. It sends out laser beams and measures the time it takes for them to bounce back. Thus, LiDAR sensors can create accurate 3D maps of the surrounding area. That’s why LiDAR is such a crucial technology for autonomous vehicles and 3D mapping applications. Top LiDAR Companies for Autonomous Vehicles There are several major players in the LiDAR industry catering to autonomous vehicles, but a few standout companies lead the pack. Velodyne LiDAR: Known as a pioneer in the industry, Velodyne is often hailed as the leader in LiDAR. With a broad product portfolio and extensive experience in the field, they have dominated the market for years. Velodyne LiDAR’s stock is publicly traded, making it one of the few public LiDAR companies. Luminar Technologies: Luminar is another heavy hitter in the LiDAR industry, specializing in long-range LiDAR sensors. Their technology is capable of detecting objects up to 250 meters away. This is a key factor in high-speed and a crucial aspect of autonomous driving. Innoviz Technologies: Innoviz is well-regarded for its high-resolution LiDAR sensors. Their solid-state design ensures durability and longevity is making them a popular choice. Which Company Will Apple Use? Well, Apple’s plans for entering the autonomous vehicle market remain largely under wraps. However, there has been significant speculation about which LiDAR company they will use. Although no official statements have been made, there are some potential contenders. Given the advanced technology and scalability, I think companies like Velodyne and Luminar are strong contenders. Who Supplies LiDAR to Tesla? There has been significant debate over Tesla’s approach to autonomous vehicle technology. This involves key factors like their decision not to use LiDAR sensors. Elon Musk has stated that Tesla’s electric vehicles will rely on camera-based systems and artificial intelligence. Thus, there’s no LiDAR supplier for Tesla at this moment, and they are ignoring its technological use. How Do Make Deepfakes? | How Generative Adversarial Networks (GANs) Work Automotive LiDAR Companies Apart from those mentioned, many other LiDAR companies are making waves in the automotive industry. Valeo, a global automotive supplier, has made significant strides in producing scalable, reliable LiDAR sensors. Companies like AEye and Quanergy also offer robust LiDAR solutions, highlighting the competitive nature of this market. The Future of LiDAR Stocks As the demand for autonomous vehicles and advanced sensing technology grows, the prospects for LiDAR company stocks look bright. Public LiDAR companies like Velodyne and Luminar have seen substantial interest from investors. They are entering the competition strongly due to their innovative technology and market leadership. Conclusion Identifying the “best” LiDAR company isn’t a straightforward task, as each has its strengths. Right now, each company caters to somewhat different needs in the market. However, Velodyne, Luminar, and Innoviz are often cited as leaders in the field. As the autonomous vehicle industry continues to grow and evolve, we can expect fierce competition in the LiDAR sector. FAQs References
Choose the Best Tool For Machine Learning with this Ultimate Guide

There are numerous machine learning tools to suit varying requirements. But the choice largely depends on the problem you’re trying to solve, data complexity, and your expertise level. These tools range from those designed specifically for beginners to more advanced software programs. Top 5 Machine Learning Tools Python: When it comes to machine learning tools for data science, Python is at the top of the list. Its simplicity, flexibility, and array of libraries, such as NumPy, Pandas, Matplotlib, and Scikit-learn, make it a top choice. This is an ideal machine learning tool for both beginners and experienced developers. TensorFlow: Created by Google, TensorFlow is an open-source library for developing and training machine learning models. It’s excellent for deep learning applications, thanks to its high-level APIs. Moreover, the tool has robust computational graph visualizations, which will certainly come in handy. PyTorch: Developed by Facebook’s artificial intelligence research group, PyTorch is another open-source library for machine learning. Is PyTorch the same as Python? Not quite. PyTorch is a library that uses Python, providing a more intuitive and easier-to-use interface for Python users. Keras: Often used in conjunction with TensorFlow, Keras is an open-source neural network library. It’s user-friendly, modular, and flexible, making it a top tool for deep learning. Scikit-Learn: A Python-based library, Scikit-learn is a great tool for machine learning. It offers a selection of supervised and unsupervised learning algorithms. These are the qualities that make it popular for machine learning tools and techniques.Backpropagation and Gradient Descent | How Does AI Learn Deep Learning: TensorFlow vs PyTorch Deep learning, a subset of machine learning, benefits immensely from specialized libraries. Among these, TensorFlow and PyTorch stand out. So, what is the best tool for deep learning? Well, we can say that it depends. TensorFlow has long been a favorite due to its comprehensive and flexible ecosystem, and its use by Google indicates its robust capabilities. However, PyTorch’s dynamic computational graph and simplicity have earned it significant popularity among researchers. Free Machine Learning Tools Fortunately for developers on a budget, there are numerous free machine learning tools available. TensorFlow, PyTorch, and Scikit-learn are all open-source and free to use. There are also tools like Weka, a user-friendly software with a collection of machine learning algorithms. This is the kind of tool that you can use freely for data mining tasks. Tools for Machine Learning in Python Python remains a favorite language for machine learning due to its readability and an extensive list of libraries. Apart from the previously mentioned TensorFlow, PyTorch, and Scikit-learn, there are other libraries as well. You can access Matplotlib for data visualization, Pandas for data manipulation, and Seaborn for statistical data visualization. Machine Learning Tools for Beginners For those just starting their machine learning journey, user-friendly tools are crucial. Python, due to its readability, is a great language to start with. Libraries like Scikit-learn and Keras are excellent as they are relatively easy to understand and use. A Comprehensive Machine Learning Software List In addition to the mentioned tools, there are several other notable mentions like: These tools provide an integrated development environment (IDE), allowing for easy-to-use, GUI-based machine learning. Image Annotation Tool: A Comprehensive Review Conclusion The best tool for machine learning depends on your needs, skills, and the problem you’re trying to solve. Each tool has its strengths and weaknesses depending on the kind of task you are handling. By understanding the capacities of each and aligning them with your requirements, you can make an informed decision. The best tool for your machine learning journey is the one that meets your needs. FAQs
Crowdsourcing Showdown: Amazon Mechanical Turk vs Crowdflower

Crowdsourcing has become an increasingly popular way for businesses and individuals to outsource small tasks to a global workforce. Two of the most well-known crowdsourcing platforms are Amazon Mechanical Turk (MTurk) and Crowdflower. While both platforms offer similar services, there are some key differences between them that may make one more suitable than the other depending on the specific needs of the user. In this article, we will compare and contrast MTurk and Crowdflower, examining the types of tasks available, the level of control that requesters have over the tasks and workers, and the pay rates for tasks. By the end of this article, readers will have a better understanding of the similarities and differences between these two popular crowdsourcing platforms, and be better equipped to choose the one that best meets their needs. Best Image Classification Models: A Comprehensive Comparison Overview of Amazon Mechanical Turk Amazon Mechanical Turk is a crowdsourcing platform that allows businesses and individuals to outsource small tasks to a global workforce. Workers on MTurk can earn money by completing these tasks, which can include tasks such as data entry, surveys, and content moderation. To use MTurk, workers can create an account and browse available tasks, selecting those that match their skills and interests. The pay rate for tasks on MTurk can vary widely, and workers are typically paid upon completion of the task. While MTurk can be a useful source of supplemental income, it may not be a reliable or sustainable option for full-time work. Workers on MTurk should carefully evaluate the pay rate and time required for each task before accepting it, and may need to develop specialized skills or knowledge to complete certain types of tasks. Stable Diffusion Image To Image. Crowdflower: Transitioning to Figure Eight and Appen Crowdflower, known as Figure Eight before being acquired by Appen, is another crowdsourcing platform. Crowdflower is a crowdsourcing platform that allows businesses and individuals to outsource small tasks to a global workforce. The platform is focused on data enrichment tasks, such as image tagging and sentiment analysis. Users can create and manage their own tasks, set their own pay rates, and communicate directly with workers. Crowdflower also offers a managed service, with a team of experts who can help users design and manage their tasks. To use Crowdflower, users can create an account and browse available tasks, selecting those that match their skills and interests. The pay rate for tasks on Crowdflower can vary widely, and workers are typically paid upon completion of the task. Overall, Crowdflower is a useful platform for those looking for specialized data enrichment tasks and a more managed service. Amazon Mechanical Turk vs. Crowdflower: A Comparative Analysis Amazon Mechanical Turk (MTurk) and Crowdflower are both crowdsourcing platforms that allow businesses and individuals to outsource small tasks to a global workforce. While there are some similarities between the two platforms, there are also some key differences that may make one platform more suitable than the other depending on the specific needs of the user. One of the main differences between MTurk and Crowdflower is the type of tasks that are available on each platform. MTurk is known for offering a wide variety of tasks, including data entry, surveys, and content moderation. Crowdflower, on the other hand, is focused more on data enrichment tasks, such as image tagging and sentiment analysis. Another difference between the two platforms is the level of control that requesters have over the tasks and the workers. MTurk allows requesters to create and manage their own tasks, set their own pay rates, and communicate directly with workers. Crowdflower, on the other hand, offers a more managed service, with a team of experts who can help requesters design and manage their tasks. The pay rates for tasks on MTurk and Crowdflower can also vary widely. While both platforms offer the ability to set pay rates for tasks, the rates may be influenced by factors such as the complexity of the task and the availability of workers. Overall, the choice between MTurk and Crowdflower will depend on the specific needs of the user. MTurk may be a better option for those looking for a wide variety of tasks and more control over the task design and worker communication. Crowdflower may be a better option for those looking for a more managed service and specialized data enrichment tasks. Looking Beyond: Alternatives to MTurk and Crowdflower For those seeking alternatives to Amazon Mechanical Turk and Crowdflower, there are other options available. Below are five alternatives to these platforms. UpWork Upwork is a freelancing platform that allows businesses and individuals to hire freelancers for a wide variety of tasks, including data entry, content writing, and graphic design. Users can post job listings and receive proposals from freelancers, and can communicate directly with freelancers to manage the project. Clickworker Clickworker is a crowdsourcing platform that offers a wide variety of tasks, including data entry, web research, and content creation. Users can create an account and browse available tasks, selecting those that match their skills and interests. The pay rate for tasks on Clickworker can vary widely, and workers are typically paid upon completion of the task. Microworkers Microworkers is a crowdsourcing platform that offers a wide variety of tasks, including data entry, surveys, and social media tasks. Users can create an account and browse available tasks, selecting those that match their skills and interests. The pay rate for tasks on Microworkers can vary widely, and workers are typically paid upon completion of the task. FAQs
Guide to Using Amazon Mechanical Turk Account in 2023

Amazon Mechanical Turk (MTurk) provides a remarkable venue for remote job opportunities, allowing you to accomplish numerous tasks. But, like all crowdsourcing marketplaces, it comes with its set of challenges. One particularly vexing issue many face is account suspension. The users are often abruptly left out in the cold with the Amazon Mechanical Turk account suspended. Navigating this setback demands a mix of understanding Amazon’s protocols and deploying swift remedies. In this post, drawing from my extensive experience and insights, I’ll unravel comprehensive solutions for those confronting an MTurk account suspension. Whether you’re a seasoned MTurk veteran or a newcomer, this guide is crafted to help you regain your footing swiftly. Let’s troubleshoot together! What is Amazon Mechanical Turk? Amazon Mechanical Turk (MTurk) is a crowdsourcing marketplace that enables businesses and individuals to outsource small tasks to a global workforce of independent contractors, known as “Turkers”. These tasks, also known as Human Intelligence Tasks (HITs), can include data labeling, image and video annotation, content moderation, and more. MTurk is designed to help businesses and individuals complete tasks that are difficult or impossible to automate, but are too small or time-consuming to be done in-house. For example, a business might use MTurk to label a large dataset of images for machine learning purposes, or to transcribe audio recordings into text. Turkers are paid for each task they complete, with payment amounts varying depending on the complexity of the task and the time required to complete it. MTurk provides a platform for businesses and individuals to post HITs, manage worker assignments, and track progress and payments. Unlocking Video Recognition with Open-Source Technology Understanding Amazon Mechanical Turk Suspension Amazon Mechanical Turk (MTurk) has a set of policies and guidelines that workers and requesters must follow in order to use the platform. If a worker or requester violates these policies, their account may be suspended or terminated. Worker accounts may be suspended for a variety of reasons, including: 1. Submitting low-quality work: Workers are expected to complete tasks accurately and to a high standard. If a worker consistently submits low-quality work, their account may be suspended. 2. Violating MTurk policies: Workers must follow MTurk’s policies and guidelines, including rules around account sharing, multiple accounts, and prohibited activities. If a worker violates these policies, their account may be suspended. 3. Engaging in fraudulent activity: Workers must not engage in any fraudulent activity, such as using bots or scripts to complete tasks, or submitting false information. If a worker is found to be engaging in fraudulent activity, their account may be suspended. When a worker’s account is suspended, they will receive an email notification explaining the reason for the suspension. The worker may be given an opportunity to appeal the suspension, but this is not guaranteed. Making Money and Withdrawing Earnings To make money on Amazon Mechanical Turk (MTurk), you need to sign up as a worker and complete Human Intelligence Tasks (HITs) posted by requesters. HITs can include tasks such as data labeling, image and video annotation, content moderation, and more. To withdraw your earnings from MTurk, you need to have a verified Amazon Payments account. You can verify your account by providing your personal information, including your name, address, and social security number (or tax identification number). Once your account is verified, you can transfer your earnings from MTurk to your Amazon Payments account. From there, you can transfer the funds to your bank account or use them to make purchases on Amazon.com. To withdraw your earnings from MTurk, follow these steps: It is important to note that there may be fees associated with transferring funds from MTurk to your Amazon Payments account, and there may be additional fees for transferring funds from your Amazon Payments account to your bank account. Be sure to check the fees and terms of service for both MTurk and Amazon Payments before withdrawing your earnings. Backpropagation and Gradient Descent | How Does AI Learn Navigating Through Amazon Mechanical Turk Now that you have a thorough understanding, it’s time to log in and start working. After your amazon mechanical turk login, you’ll land on a dashboard showing available HITs. You can select tasks that align with your skills and start earning. Reference links:
Labelbox vs Roboflow: A Comparative Study of AI Training Platforms

In an era dominated by machine learning advancements, the significance of efficient data annotation and model training platforms cannot be overstated. Labelbox and Roboflow have emerged as two frontrunners in this realm, addressing unique challenges faced by developers. While Labelbox boasts an advanced suite of annotator tools and a rich history, accentuated by its market dominance and intricate ontology, Roboflow shines with its comprehensive computer vision developer framework, spanning from data collection to deployment. As businesses pivot towards AI-driven solutions, it becomes imperative to delve deep into these platforms, discerning their strengths, features, and distinct use-cases. Dive in as we compare and contrast the capabilities of Labelbox and Roboflow, guiding you towards the right fit for your AI needs. What is Roboflow? Roboflow is an advanced Computer Vision development framework that streamlines the pipeline from data acquisition to preprocessing, and sophisticated model training methodologies. Roboflow offers publicly accessible datasets for immediate utilization, and also provides interfaces for users to upload bespoke datasets. It boasts compatibility with multiple annotation schemas. During the data preprocessing phase, it undergoes several transformation processes which include adjustments in image orientation, dimension resizing, contrast optimization, and diverse data augmentation techniques. The framework facilitates seamless collaboration by enabling workflow coordination across team members. For model training, it comes equipped with a comprehensive library of pre-trained architectures, including but not limited to EfficientNet, MobileNet, Yolo, TensorFlow, and PyTorch. Subsequent to training, deployment and visualization toolsets are available, ensuring coverage of the entire cutting-edge computer vision pipeline. Roboflow is ubiquitously employed across diverse sectors in the computer vision domain, catering to applications such as gas leak detection, differentiation between plants and weeds, aviation maintenance, estimating roof damages, processing satellite imagery, autonomous vehicular systems, traffic analysis, waste management, and a plethora of other use cases. What is Labelbox? LabelBox platform offers state-of-the-art AI-driven utilities tailored for automated data annotation, which streamlines the labelling task and facilitates the training of models optimized for active learning. Furthermore, it boasts API integration capabilities. Through LabelBox, one can seamlessly incorporate team members into the annotation pipeline, fostering collaboration across diverse workflows. It’s versatile in its data-handling capacities, supporting a myriad of annotation format imports and exports. With its sophisticated ontology design, it ensures the delivery of high-fidelity labels, reducing the margin of error. On the infrastructure front, it’s compatible with predominant cloud providers, including Azure, GCP, and Sagemaker, among others. Key Features: Conclusion: While both Labelbox and Roboflow offer tools beneficial for managing and processing data, they cater to slightly different niches within the field. Labelbox excels in automating the data labeling process and supporting collaboration, while Roboflow provides a more end-to-end solution for computer vision development, from data collection to model deployment. The choice between them would be largely dependent on specific project needs and requirements.
Standardization vs Normalization: A Guide to Data Cleaning and Processing Techniques
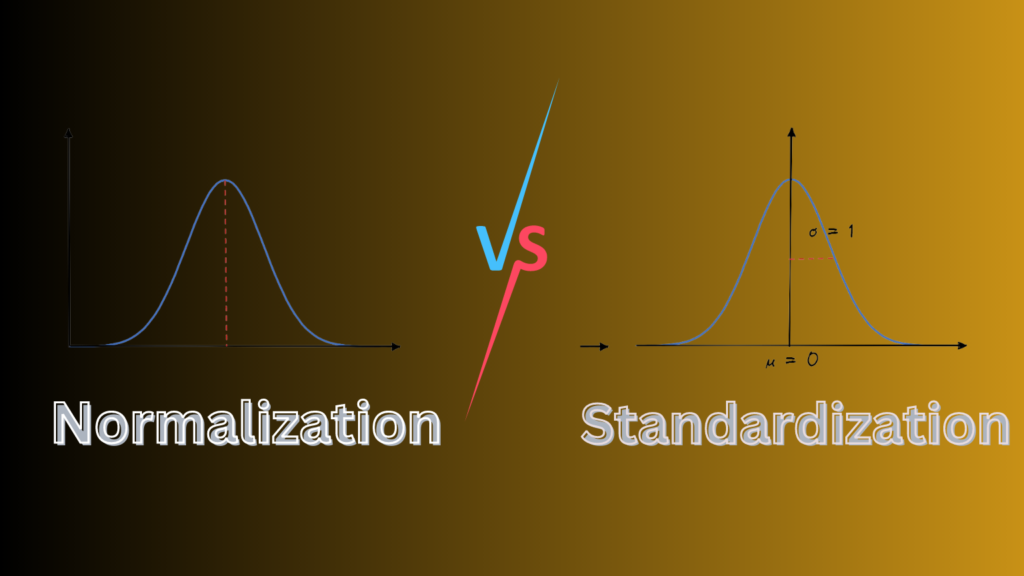
Data cleaning and processing are essential steps in any statistical analysis. Raw data often contains systematic variations that can lead to poor interpretation and inaccurate conclusions. To overcome this challenge, various statistical techniques like transformation, standardization, and normalization are used to clean and process data. In this article, we will explore the differences between standardization vs normalization and how they can be used to improve data analysis. Best Image Classification Models: A Comprehensive Comparison What is Normalization? Normalization is a technique used to transform data into a common scale. This technique is useful when the data has different ranges or scales. Normalization involves scaling the data to a range of 0 to 1. This process is achieved by subtracting the minimum value from the data and dividing by the range of the data. Normalization is also known as min-max normalization. Normalization is useful when we want to compare the relative importance of different variables. For example, if we want to compare the performance of different students in a class, we need to normalize the data to ensure that the comparison is fair. Normalization is also useful when we want to reduce the impact of outliers in the data. Outliers can have a significant impact on the analysis of data. Normalization helps to reduce the impact of outliers by scaling the data to a common range. Supervised Vs Unsupervised Machine Learning What is Standardization? Standardization is a technique used to transform data into a standard scale. This technique is useful when the data has different units of measurement or scales. Standardization involves subtracting the mean of the data and dividing by the standard deviation. This process results in data with a mean of zero and a standard deviation of one. Standardization is also known as z-score normalization. Standardization is useful when comparing data from different sources or when the data has different units of measurement. For example, if we want to compare the heights of individuals from different countries, we need to standardize the data to ensure that the comparison is fair. Standardization is also useful when we want to identify outliers in the data. Outliers are data points that are significantly different from the rest of the data. Standardization helps to identify outliers by transforming the data into a standard scale. Standardization vs Normalization Standardization and normalization are both useful techniques for data cleaning and processing. However, they have different applications and are used in different situations. Standardization is useful when the data has different units of measurement or when we want to identify outliers in the data Normalization, on the other hand, is useful when the data has different ranges or scales or when we want to compare the relative importance of different variables. One of the main differences between standardization and normalization is the resulting scale of the data. Standardization transforms the data into a standard scale with a mean of zero and a standard deviation of one. Normalization scales the data to a range of 0 to 1. Another difference between standardization and normalization is the impact of outliers on the data. Standardization can be sensitive to outliers because it is based on the mean and standard deviation of the data. Outliers can significantly impact the mean and standard deviation, which can affect the results of the analysis. Normalization is less sensitive to outliers because it is based on the range of the data. Outliers have less impact on the range of the data, which makes normalization more robust to outliers. When to Use Standardization vs Normalization The choice between standardization and normalization depends on the nature of the data and the analysis. Standardization is useful when the data has different units of measurement or when we want to identify outliers in the data. Normalization is useful when the data has different ranges or scales or when we want to compare the relative importance of different variables. For example, if we want to compare the performance of different students in a class, we can use normalization to ensure that the comparison is fair. We can normalize the data by scaling the grades of each student to a range of 0 to 1. This process will ensure that the comparison is fair and that the relative importance of each student’s grade is preserved. On the other hand, if we want to compare the heights of individuals from different countries, we can use standardization to ensure that the comparison is fair. We can standardize the data by subtracting the mean height of the data and dividing by the standard deviation. This process will ensure that the comparison is fair and that the impact of outliers is reduced. Conclusion Data cleaning and processing are essential steps in any statistical analysis. Standardization and normalization are two useful techniques for data cleaning and processing. Standardization is useful when the data has different units of measurement or when we want to identify outliers in the data. Normalization is useful when the data has different ranges or scales or when we want to compare the relative importance of different variables. The choice between standardization and normalization depends on the nature of the data and the analysis. By understanding the differences between standardization and normalization, we can make informed decisions about which technique to use and when to use it. Ultimately, the goal of data cleaning and processing is to ensure that our data is accurate, reliable, and useful for making informed decisions.
Numerical vs Categorical Data: Understanding the Differences and Importance in Research Studies

When conducting research studies, it is essential to collect and analyze data effectively to draw meaningful conclusions. Data can be broadly classified into two types: numerical and categorical. In this article, we will explore the differences between these two types of data and their importance in research studies. Best Data Labeling Company in 2023 Numerical Data Numerical data, also known as quantitative data, is data that can be measured and expressed in numbers. This type of data is continuous and can be further classified as discrete or continuous. Discrete data is data that can only take on specific values, such as the number of people in a room. Continuous data, on the other hand, can take on any value within a range, such as height or weight. Numerical data is often analyzed using statistical methods such as mean, median, and mode. These methods help researchers to summarize and interpret the data effectively. Categorical Data Categorical data, also known as qualitative data, is data that cannot be measured and expressed in numbers. This type of data is non-continuous and can be further classified as nominal or ordinal. Nominal data is data that is expressed in categories, such as gender or race. Ordinal data is data that can be arranged in a specific order, such as the level of education. Categorical data is often analyzed using frequency tables and charts. These methods help researchers to summarize and present the data effectively. The Importance of Numerical vs Categorical Data in Research Studies Both numerical and categorical data are essential in research studies. Numerical data provides researchers with precise measurements and allows for statistical analysis. This type of data is often used in scientific studies, such as clinical trials, to measure the effectiveness of treatment. Categorical data, on the other hand, provides researchers with information about the characteristics of a population. This type of data is often used in social science studies, such as surveys, to understand the attitudes and behaviors of a group of people. Collecting and Analyzing Numerical Data When collecting numerical data, it is essential to ensure that the data is accurate and reliable. This can be achieved by using standardized measurement tools and ensuring that the data is collected consistently across all participants. Once the data is collected, it can be analyzed using statistical methods such as mean, median, and mode. These methods help researchers to summarize the data and draw meaningful conclusions. It is important to note that the choice of statistical method will depend on the type of data collected and the research question being addressed. For example, if the research question is to determine the average height of a population, the mean would be an appropriate statistical method to use. However, if the data is skewed, the median may be a better measure of central tendency. Collecting and Analyzing Categorical Data When collecting categorical data, it is important to ensure that the categories are well-defined and mutually exclusive. This can be achieved by using standardized questionnaires or surveys. Once the data is collected, it can be analyzed using frequency tables and charts. These methods help researchers to summarize the data and identify patterns or trends. For example, if the research question is to determine the prevalence of a certain disease in a population, a frequency table can be used to display the number of people with the disease and the number of people without the disease. Visualizing Numerical and Categorical Data Visualizing data is an effective way to communicate research findings to a wider audience. There are several ways to visualize numerical and categorical data, including histograms, scatter plots, bar charts, and pie charts. Histograms are used to display the distribution of numerical data. They show the frequency of data points within a specific range. Scatter plots are used to display the relationship between two numerical variables. They show how one variable changes in response to changes in the other variable. Bar charts and pie charts are used to display categorical data. Bar charts show the frequency of data points within each category. Pie charts show the proportion of data points within each category. Conclusion Numerical and categorical data are essential in research studies. Numerical data provides precise measurements and allows for statistical analysis, while categorical data provides information about the characteristics of a population. Collecting and analyzing data effectively is crucial to drawing meaningful conclusions from research studies. Visualizing data is an effective way to communicate research findings to a wider audience. By understanding the differences between numerical and categorical data, researchers can choose the appropriate methods to collect, analyze, and present their data. References
Lemmatization vs Stemming

A Comparison of Language Modeling Techniques for Document Retrieval! As the amount of data and information collection continues to grow, it has become increasingly important to develop tools that can access information with ease. One such tool is language modeling, which involves techniques such as stemming and lemmatization to improve document retrieval precision. In this article, we will explore the differences between Lemmatization vs Stemming and compare their effectiveness in improving document retrieval. Stemming Stemming is a language modeling technique that involves reducing all words with the same stem to a common form. For example, the words “jumping,” “jumps,” and “jumped” would all be reduced to the stem “jump.” This technique is useful in document retrieval because it allows for more efficient searching of documents that contain variations of the same word. Lemmatization Lemmatization, on the other hand, involves removing inflectional endings and returning the base or dictionary form of a word. For example, the word “am,” “is,” and “are” would all be reduced to the base form “be.” This technique is more advanced than stemming because it takes into account synonyms of a word, resulting in more relevant documents being retrieved. Comparing Lemmatization vs Stemming To compare the effectiveness of stemming and lemmatization, a search engine was developed and algorithms were tested based on a test collection. Both mean average precisions and histograms indicate that stemming and lemmatization outperform the baseline algorithm. However, lemmatization produced better precision compared to stemming, with the differences being insignificant. Both stemming and lemmatization performed better than the baseline technique at both the document levels. This indicates that when queries are processed using language modeling techniques, they yield documents that are more relevant compared to queries which are not processed. Best Image Classification Models: A Comprehensive Comparison Why Use Language Modeling Techniques? Speed and relevancy are essential in the retrieval of information, and information seekers look for ways to improve this aspect of the retrieval process. Language modeling techniques such as stemming and lemmatization have been shown to improve document retrievals. However, there are still a lot of non-relevant documents being retrieved, even with these techniques being applied to search queries. Limitations of Language Modeling Techniques While language modeling techniques such as stemming and lemmatization can improve document retrieval, there are still limitations to these techniques. Conclusion In conclusion, both stemming and lemmatization are effective language modeling techniques for improving document retrieval precision. However, lemmatization is more advanced and produces better precision compared to stemming. Information seekers can benefit from using these techniques to improve the speed and relevancy of their document retrievals. While there are still limitations to these techniques, future studies can explore other test collections and techniques to further improve the retrieval process. FAQs References
What is Amazon Mechanical Turk Used For? Details to Know

Amazon Mechanical Turk (MTurk) is a crowdsourcing platform that allows businesses and researchers to outsource small tasks to a global workforce. MTurk has a wide range of uses, from data entry and content moderation to academic research and machine learning. Some of the most common uses of MTurk include conducting surveys, labeling images and videos, transcribing audio recordings, and testing software and websites. MTurk is also used by businesses to gather customer feedback, verify product information, and perform market research. With its flexible and scalable workforce, MTurk has become a valuable tool for businesses and researchers looking to outsource small, repetitive tasks and gather data quickly and efficiently. A Dive into Amazon Mechanical Turk Amazon Mechanical Turk (MTurk) is an online platform where businesses, researchers, and individuals (known as Requesters) meet. You can assign and complete tasks that require human intelligence to workers (Turkers) worldwide. These tasks referred to as Human Intelligence Tasks (HITs), are too nuanced for artificial intelligence to perform. However, the good thing is that humans can handle them with relative ease. One of the most common types of work you’ll find on MTurk is data entry. Amazon Mechanical Turk data entry tasks, typically involve entering provided data into a designated system or platform. This offers a straightforward way for newcomers and experienced professionals to earn income. However, the job range is wide, from transcribing audio files to classifying objects in images or participating in academic research studies. So, is Amazon Mechanical Turk safe? Absolutely. Amazon is a highly reputable platform known for its robust security measures. While safety is guaranteed, it’s also essential to know your potential earnings on this platform.Precision vs Accuracy Machine Learning: A Detailed Examination Unlocking the Amazon Mechanical Turk Pay Unlocking the Amazon Mechanical Turk pay can be a challenge for some workers, as the pay rates for tasks on the platform can be low and the competition for work can be high. However, there are several strategies that workers can use to increase their earnings on MTurk. One strategy is to focus on tasks that pay well and are in high demand, such as transcription, data entry, and content moderation. Workers can also look for tasks that offer bonuses or incentives for high-quality work, or that require specialized skills or knowledge. Another strategy is to work efficiently and quickly, completing tasks as quickly and accurately as possible to maximize earnings. Workers can also use tools and scripts to automate repetitive tasks and streamline their workflow. Networking with other MTurk workers and joining online communities can also be helpful, as workers can share tips and strategies for finding high-paying tasks and improving their skills. Supervised Vs Unsupervised Machine Learning Working on MTurk and Withdrawing Earnings Working on Amazon Mechanical Turk (MTurk) is a flexible and accessible way to earn money by completing small tasks online. Here is a short guide on how to get started and withdraw your earnings: Navigating Amazon Mechanical Turk Once you complete your registration, you’re ready for your Amazon Mechanical Turk login. After logging in, you’ll see your dashboard with a list of available HITs. You can filter tasks based on pay, and time required and find jobs that suit your skills. An example of a mechanical Turk task might be transcribing a short audio clip or identifying objects in an image. You can also take up tasks that involve answering a survey for market research. FAQs