
Best Image Segmentation Models: A Comprehensive Guide

Image segmentation is a process of partitioning an image into multiple segments, making it easier to analyze and understand. It is a valuable tool in many fields, including healthcare, traffic analysis, and pattern recognition. There are different techniques and approaches for image segmentation, each with its own advantages and disadvantages. In this article, we will explore some of the best image segmentation models and their applications. Supervised Vs Unsupervised Machine Learning Best Image Segmentation Models Threshold-Based Segmentation Threshold-based segmentation is one of the simplest and most commonly used techniques for image segmentation. It involves setting a threshold value and classifying pixels based on their intensity values. Pixels with intensity values above the threshold are classified as one segment, while those below the threshold are classified as another segment. This technique is useful for images with clear boundaries between objects and background. Threshold-based segmentation is widely used in medical image processing, such as identifying tumors and other abnormalities. It is also used in traffic analysis for vehicle detection and tracking. Graph-Based Segmentation Graph-based segmentation involves representing an image as a graph, where each pixel is a node, and the edges represent the relationship between pixels. The graph is then partitioned into segments using algorithms such as a minimum cut or normalized cut. This technique is useful for images with complex structures and textures. Graph-based segmentation is widely used in computer vision applications, such as object recognition and tracking. It is also used in medical image processing for identifying anatomical structures. Morphological-Based Segmentation Morphological-based segmentation involves using mathematical morphology to extract features from an image. This technique is useful for images with irregular shapes and structures. Morphological-based segmentation involves operations such as dilation, erosion, opening, and closing to extract features from an image. Morphological-based segmentation is widely used in medical image processing for identifying anatomical structures. It is also used in traffic analysis for vehicle detection and tracking. Edge-Based Segmentation Edge-based segmentation involves detecting edges or pixels between different regions. The condition for different regions may be a rapid transition of intensity. So those pixels are extracted and linked together to form a closed boundary. This technique is useful for images with clear boundaries between objects and backgrounds. Edge-based segmentation is widely used in computer vision applications, such as object recognition and tracking. It is also used in medical image processing for identifying anatomical structures. Clustering-Based Segmentation Clustering-based segmentation involves grouping pixels into clusters based on their similarity. There are different clustering techniques, including: K-means clustering involves partitioning pixels into K clusters based on their similarity. Fuzzy c-means clustering is similar to K-means clustering, but it allows pixels to belong to multiple clusters with different degrees of membership. Subtractive clustering involves subtracting the density of the data points to obtain the cluster centers. Expectation Maximization clustering involves estimating the parameters of a statistical model to obtain the cluster centers. DBSCAN clustering involves grouping pixels into clusters based on their density. Clustering-based segmentation is widely used in various fields, including healthcare, traffic analysis, and pattern recognition. In healthcare, it is used for medical image processing, such as identifying tumors and other abnormalities. In traffic analysis, it is used for vehicle detection and tracking. In pattern recognition, it is used for object recognition and classification. Bayesian-Based Segmentation Bayesian-based segmentation involves using probability to construct models based on the image data. This technique involves estimating the probability distribution of the image data and using it to segment the image. Bayesian-based segmentation is useful for images with complex structures and textures. Bayesian-based segmentation is widely used in various fields, including healthcare, traffic analysis, and pattern recognition. In healthcare, it is used for medical image processing, such as identifying tumors and other abnormalities. In traffic analysis, it is used for vehicle detection and tracking. In pattern recognition, it is used for object recognition and classification. Neural Network-Based Segmentation Neural network-based segmentation involves using artificial neural networks to segment images. This technique involves training a neural network to recognize patterns in the image data and using it to segment the image. Neural network-based segmentation is useful for images with complex structures and textures. Neural network-based segmentation is widely used in various fields, including healthcare, traffic analysis, and pattern recognition. In healthcare, it is used for medical image processing, such as identifying tumors and other abnormalities. In traffic analysis, it is used for vehicle detection and tracking. In pattern recognition, it is used for object recognition and classification. Applications of Image Segmentation Image segmentation has many applications in various fields. In healthcare, it is used for medical image processing, such as identifying tumors and other abnormalities. In traffic analysis, it is used for vehicle detection and tracking. In pattern recognition, it is used for object recognition and classification. In addition to these applications, image segmentation is also used in robotics, where it is used for object recognition and tracking. It is also used in satellite imagery, where it is used for land cover classification and change detection. In the field of computer graphics, it is used for image editing and compositing. Conclusion In conclusion, image segmentation is a valuable tool in many fields, and there are different techniques and approaches for image segmentation. Threshold-based segmentation, graph-based segmentation, morphological-based segmentation, edge-based segmentation, clustering-based segmentation, Bayesian-based segmentation, and neural network-based segmentation are some of the best image segmentation models. Each technique has its own advantages and disadvantages, and the choice of technique depends on the specific needs of the application. Image segmentation has many applications in various fields, including healthcare, traffic analysis, pattern recognition, robotics, satellite imagery, and computer graphics. With the advancement of technology, image segmentation techniques are becoming more sophisticated and accurate, making it easier to analyze and understand complex images. FAQs References
Discovering Data: Best Websites For Datasets

A model’s brilliance is often limited by the quality of its data. In simple words, data is the lifeblood of our algorithms. However, finding the right dataset, one that aligns with your specific needs, can often feel like hunting for a needle in a haystack. Fortunately, numerous websites are now offering a vast array of datasets for a multitude of purposes. In this blog post, I’ve compiled a list of the most resourceful websites offering datasets spanning diverse domains and complexities. Whether you’re a seasoned pro or a budding data scientist, these data treasures has something to offer you! Top 20 Websites For Datasets 1. Quandl: Dive into an extensive bank of Economic and Financial figures. While a lion’s share of the data is gratis, a select few come at a cost. 2. Academic Torrents: A resourceful platform boasting data behind scientific publications. The extensive collection is up for grabs without any fee. 3. Data.gov: An assembly of comprehensive datasets courtesy of US Government entities. Its range spans from Education to Climate and much more. 4. UCI Machine Learning Repository: Managed by the esteemed University of California, Irvine, it’s home to 400+ datasets targeting the Machine Learning realm. 5. Google Public Datasets: Google’s Cloud Platform offers a wealth of datasets. Harness BigQuery to sift through them. Bonus? Your first 1TB of queries won’t cost a dime. 6. GitHub’s Datasets Haven: A plethora of intriguing datasets awaits you here, including Climate Statistics, Plane Crash records, and more. 7. Socrata: A platform known for its pristine datasets, spanning domains from Government insights to Radiation analyses. 8. Kaggle Datasets: With Kaggle’s reputation in the data arena, it’s no surprise they showcase an array of open-source data across myriad sectors. 9. World Bank’s Offerings: Courtesy of the World Bank, you can access various tools and datasets, including Education Indices and an Open Data Catalog. 10. Reserve Bank of India (RBI): From Money Market Operations to Banking products, RBI ensures a thorough data provision. 11. FiveThirtyEight: Their GitHub repository is a goldmine of diverse datasets. Each dataset is meticulously explained, with the FIFA dataset being a particular standout. 12. AWS Datasets: As a big player, AWS is steadily making its mark with an ever-growing dataset collection. 13. YouTube Video Dataset: This labeled dataset showcases 8 million video IDs along with associated data. 14. Analytics Vidhya: Engage with datasets downloadable from their numerous data-hack challenges. 15. KDD Cups: Organized by ACM, this competition in Knowledge Discovery and Data Mining presents datasets complete with thorough explanations. 16. Data Driven: With a focus on societal impact, Data Driven’s competitions offer intriguing datasets to data scientists. 17. MNIST Dataset: A unique dataset featuring hand-drawn digits, boasting approximately 60,000 samples. 18. ImageNet: Dive into a vast image database, with photos organized as per the WordNet hierarchy. 19. Yelp’s Collection: Hosting 8 million+ reviews, it’s an invaluable resource for Text Classification projects. 20. Airbnb’s Data Vault: An exhaustive listing of data straight from Airbnb’s offerings. Data Sets to Analyze for Projects When it comes to finding datasets for projects, consider what you want to achieve with your analysis. For machine learning projects, MNIST (handwritten digits) or CIFAR-10 (object recognition) are good starting points. For statistics or data visualization, consider using the Titanic dataset on Kaggle or the Gapminder dataset. In conclusion, finding the right dataset is crucial in the realm of data analysis. Whether you’re a data science novice, a researcher, or a seasoned data scientist, the aforementioned platforms offer a multitude of high-quality datasets that can cater to your specific needs. So, happy data hunting, and may your insights be rich and your conclusions insightful! FAQs 1. What is a website dataset? A website dataset refers to a collection of data that is available on a website for download and use. These datasets can cover a wide variety of topics and can come in various formats such as CSV, JSON, or SQL. 2. Are all datasets on Google’s Public Datasets platform free? Yes, all datasets available on Google’s Public Datasets platform are free to use. They cover various sectors and can be integrated directly with Google’s data analysis tools for easier use. 3. Where can students find free datasets? UC Irvine’s Machine Learning Repository and Data.gov are excellent platforms where students can find free datasets for their projects. Additionally, platforms like Kaggle and GitHub also host a wide variety of datasets that can be used. 4. Are there any free datasets available for use? Yes, many platforms offer free datasets. These include Google Public Datasets, Kaggle, UC Irvine’s Machine Learning Repository, Data.gov, GitHub, the U.S. Census Bureau, and the European Union Open Data Portal, among others. References
Accelerate Your Career with the Best Data Science Bootcamps

In a world that increasingly revolves around data, the demand for data scientists—experts who can turn that data into insights—is growing. As traditional education systems struggle to keep up with the fast-paced industry, alternative learning routes like data science boot camps have emerged. These boot camps offer intensive, focused training in data science in a short amount of time. But with a plethora of options, how can you find the best data science bootcamps? This article will guide you through the process, answering crucial questions and highlighting some top contenders.CES 2023 | When will robots take over the world? What is the Best Data Science Boot Camp? While the term “best” is relative and largely depends on individual needs, certain boot camps consistently rank high based on their comprehensive curriculum, skilled instructors, job placement success, and student reviews. One such boot camp is the a Data Science Bootcamp. This program stands out with its job placement guarantee and one-on-one mentoring from industry professionals. Springboard’s rigorous curriculum includes both theoretical instruction and practical projects, ensuring students acquire the necessary skills for a career in data science. Is a Bootcamp Enough for Data Science? This question often arises among individuals considering alternative learning paths. Can a boot camp, typically lasting only a few weeks or months, equip you with the skills required for a data science career? The answer is yes and no. Boot camps can provide an intensive, concentrated introduction to data science. They cover key concepts and skills, offer practical projects, and sometimes even provide career services like networking and job placement assistance. For individuals with some background in mathematics or coding, a boot camp can be an effective way to quickly transition into data science. However, data science is a vast field that continues to evolve. Even after a boot camp, you’ll likely need to continue learning and expanding your skills, either on the job or through additional courses.CES 2023 Robotics Innovation Awards | Best New Robot Ventures Which Training Institute is Best for Data Science? In addition to boot camps, several reputable training institutes offer comprehensive data science courses. Institutions like General Assembly, DataCamp, and Coursera are often lauded for their extensive online data science courses. These platforms offer flexibility and a wide array of courses catering to different skill levels—from beginners to experienced professionals. Free and In-Person Data Science Boot Camps While many boot camps come with hefty price tags, there are also free options available. These free courses, like the one offered by Dataquest, may not provide as much personalized attention or career services, but they still cover important data science concepts. For individuals who prefer in-person learning, options are available too. Schools like General Assembly and Metis offer in-person data science boot camps in various cities across the U.S. However, due to COVID-19, many of these programs have temporarily shifted online. Data Science Boot Camp Near Me When seeking a data science boot camp, location is an important factor for those preferring in-person learning. Boot camps are available in major cities across the globe, from New York to London to Singapore. Using simple online searches or platforms like CourseReport or Switchup, you can find boot camps near your location. Data Science Bootcamp Cost The cost of data science boot camps varies greatly, ranging from free to over $10,000. Factors influencing cost include the length of the program, whether it’s in-person or online, and the resources provided, such as career services or mentorship. While cost is an important consideration, it’s crucial to evaluate the return on investment. Many high-quality boot camps offer job placement guarantees or tuition refunds, making them a worthy investment. Conclusion Finding the best data science boot camp involves considering a variety of factors, including curriculum depth, format, cost, and your individual career goals. While a boot camp can provide a robust foundation, remember that in the ever-evolving field of data science, learning is a lifelong journey. Whether you choose a free online course, an intensive in-person boot camp, or a comprehensive program at a training institute, the best boot camp is the one that suits your learning style, meets your needs, and empowers you to unlock the potential of data. FAQs References
Streamlining Data Labeling with Artificial Intelligence Annotation

Data annotation, in the context of artificial intelligence, refers to the process of labeling or tagging data. The purpose behind it is to make data discernible to machines. Machine learning models, a subset of AI, learn from the data they are fed, while data annotation acts as the crucial step that guides this learning process. Imagine giving a book to a person who doesn’t understand the language it’s written in. The book, despite its valuable information, is useless to the reader. In a similar vein, raw data – whether it be text, images, or audio – is meaningless to AI models. They need the data to be annotated or labeled to derive patterns and learn from them. Subsequently, make accurate predictions or decisions based on the received data. Unveiling the Link Between Artificial Intelligence and Data Annotation The link between artificial intelligence and data annotation is that AI can be used to automate the process of data annotation. This is particularly useful in fields such as medical imaging, where large amounts of data need to be annotated in order to train machine learning models. Automated data annotation can save time and reduce errors compared to manual annotation, and can also improve the accuracy of machine learning models. Various AI-based tools and techniques have been developed for data annotation, including natural language processing algorithms for text annotation and deep learning-based imaging segmentation for image annotation. Supervised Vs Unsupervised Machine Learning Exploring Data Annotation Examples There are many examples of data annotation, including: 1. Image annotation: This involves adding metadata to images, such as identifying objects or regions of interest within the image, labeling images with descriptive tags, or adding bounding boxes around objects. 2. Text annotation: This involves adding metadata to text data, such as identifying named entities (e.g. people, places, organizations), tagging text with descriptive labels, or adding sentiment scores to text. 3. Audio annotation: This involves adding metadata to audio data, such as identifying speech or music segments within the audio, labeling audio with descriptive tags, or adding timestamps to audio segments. 4. Video annotation: This involves adding metadata to video data, such as identifying objects or regions of interest within the video, labeling video with descriptive tags, or adding timestamps to video segments. 5. Sensor data annotation: This involves adding metadata to sensor data, such as identifying patterns or anomalies within the data, labeling data with descriptive tags, or adding timestamps to data segments. Delving into Data Annotation Tools Several tools facilitate data annotation, including open-source options like LabelImg for image annotation and Doccano for text annotation. Commercial tools like Labelbox, Dataturks, and others provide additional features. Examples of these features are collaborative annotation, progress tracking, and quality control. Best Image Classification Models: A Comprehensive Comparison FAQs References
Best Practices For Machine Learning Applications: A Comprehensive Guide

Cutting-edge algorithm is only half the battle won; the key lies in the application. Crafting robust machine learning applications demands more than just technical prowess—it requires a diligent adherence to best practices. As we navigate 2023, it’s essential to not just keep up, but to be at the forefront of these evolving standards. In this blog post, I present a comprehensive guide delineating the gold standards for ML applications. Whether you’re an old hand or charting new territories, this guide promises invaluable insights.CES Robotics | Where are they now? What are the Best Practices in Machine Learning? The journey from raw data to valuable insights is meticulous but requires an understanding of the basic building blocks of ML. Therefore, before we delve into the best practices, let’s take a moment to understand the basics. Below are the five basic steps used to perform a machine learning task. Data Collection: The process begins with the accumulation of a vast amount of high-quality, relevant data. These data sets serve as the basis for training and testing the machine learning models. Data Preparation: Data is then cleaned, preprocessed, and transformed into a format that can be utilized effectively by the ML models. This step often involves handling missing or outlier data, feature scaling, and feature extraction. Model Selection: Here, the appropriate ML algorithm or model is chosen based on the problem at hand. However, it also involves the quality and nature of the data and the desired output. Training and Validation: The chosen model is trained with the prepared data. The trained model is then validated against a validation dataset to tune the model’s parameters. Evaluation and Deployment: Finally, the trained model is evaluated using a test data set. And upon reaching satisfactory performance levels, the model is deployed to solve real-world problems. Now let’s pivot to the best practices that can lead to a successful machine-learning application.AI documentary: The dangers of artificial intelligence | AI Ethics Abiding by the ’10 Times Rule’ in Machine Learning The ’10 times rule’ in machine learning is a widely accepted rule of thumb. It suggests that the number of instances (rows) in your dataset should be 10 times the number of features (columns). This practice helps in avoiding overfitting and aids in making accurate predictions. Nonetheless, the ’10 times rule’ should be taken as a guideline rather than a rigid boundary. Therefore, considerations should be made based on the complexity of the model and the nature of the task. Ensuring Quality and Diversity in Data Quality and diversity in data form the bedrock of any successful ML application. Noisy, incomplete, and unrepresentative data can lead to inaccurate and biased results. Emphasize the collection of high-quality, diverse data that represents all aspects of the problem space. Validation Strategy and Cross-Validation Validation strategy plays a crucial role in the model selection process. It’s essential to have a robust validation strategy to assess the performance of the ML model. One such strategy is k-fold cross-validation, which ensures the model’s performance. It ensures that performance is not dependent on a specific partitioning of the data. Regularization and Hyperparameter Tuning Regularization techniques prevent overfitting by imposing penalties on the complexity of the model. The choice of regularization parameter is often made via hyperparameter tuning. This is a process that involves selecting the set of optimal hyperparameters for a learning algorithm. Machine Learning Code Best Practices Properly documented and modularized code is a hallmark of successful machine learning applications. Clear, reusable, and version-controlled code helps in maintaining the project and troubleshooting issues. But its biggest role is in improving the model’s performance over time. Employing coding practices can significantly enhance the quality and readability of your ML code. Best practices include peer reviews, consistent naming conventions, and adhering to PEP-8 guidelines for Python. Deep Learning Best Practices Deep learning, a subset of machine learning, requires its own set of best practices. These may include the use of appropriate activation functions and proper initialization of weights. Additionally, batch normalization and the use of dropout layers for regularization are recommended. Furthermore, leveraging transfer learning can accelerate the training process and enhance model performance. This is where pre-trained models are used as the starting point. Evaluation Metrics The selection of appropriate evaluation metrics for the ML model is paramount. These metrics should align with the business objectives and provide meaningful insights into the model’s performance. Common metrics include accuracy, precision, recall, F1 score for classification problems, and mean absolute error. Some other metrics are root mean squared errors for regression problems. Emphasizing Explainability and Ethics Finally, a successful machine-learning application must prioritize explainability and ethical considerations. Models should be interpretable, transparent, and fair, with mechanisms to identify and mitigate bias. Furthermore, respecting user privacy and using data responsibly should be at the forefront of every ML application. Conclusion To summarize, the best practices for machine learning applications are an amalgamation of meticulous data handling, effective model selection and tuning, good coding practices, careful performance evaluation, and an ethical and responsible approach. Embracing these practices not only maximizes the potential of ML applications but also paves the way for responsible and impactful AI. FAQs References
Lidar Uses: An Exploration of Its Uses
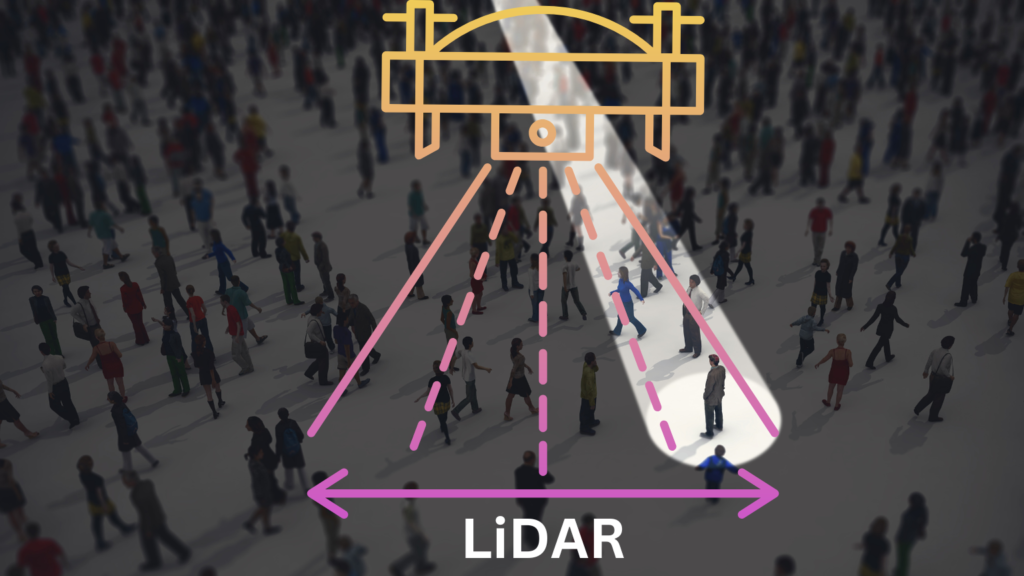
Light Detection and Ranging, universally known as LiDAR, is transforming the ways of navigation. Once relegated to niche applications, today Lidar stands at the vanguard of a multitude of sectors. It’s reshaping our perception and interaction with the physical world. As 2023 unfolds, the scope and applications of Lidar technology continue to expand, making it an opportune moment to explore its multifaceted uses. In this post, we will be exploring the depths of Lidar’s capabilities. I’ll illuminate the myriad ways Lidar is shaping our world and its potential uses for tomorrow. Unveiling the Main Benefit of LiDAR The main benefit of using LiDAR lies in its ability to generate accurate, high-resolution 3D representations of physical environments. This accuracy stems from its advanced technology, which emits pulses of light. Light is emitted up to a million per second and then LiDAR measures the precise time. This is the time each pulse takes to bounce back after hitting an object. This provides highly detailed, real-time data, regardless of environmental conditions or the time of day. Training Data vs Validation Data: What is the Difference Navigating the Terrain: Where is LiDAR Most Useful? LiDAR’s utility extends across a plethora of sectors, ranging from autonomous vehicles to environmental monitoring. Autonomous Vehicles: Perhaps the most notable use of LiDAR is in autonomous or self-driving vehicles. These vehicles rely on LiDAR sensors to create a detailed 3D map of their surroundings. This enables the vehicles to detect obstacles, lane markings, and the road’s curvature, even under poor visibility conditions. Surveying and Mapping: LiDAR is an invaluable tool for geospatial professionals. It aids in mapping complex terrains, modeling city structures, and exploring archaeological sites. By penetrating foliage, LiDAR can also reveal ground features hidden by dense vegetation. Agriculture: Farmers and agricultural scientists employ LiDAR to gather detailed topographical and vegetation data. These data inform irrigation planning, crop management, and yield estimation. Atmospheric Research: Meteorologists and climate scientists use LiDAR to study atmospheric properties. They also use it to study the distribution of particles and gases, which is used for weather prediction and climate modeling. Sailing Through the Waves with Bathymetric LiDAR One remarkable application of LiDAR technology is bathymetric LiDAR. This is the technological tool used to measure seafloor and riverbed depth. Unlike typical LiDAR, which uses near-infrared light, bathymetric LiDAR uses green light wavelengths that can penetrate water. It is an efficient way of mapping large coastal and river areas. The technology aids in underwater detection, seafloor mapping, and flood risk management. Different Shades of Perception: Types of LiDAR There are two main types of LiDAR—airborne and terrestrial—each with specific uses. Airborne LiDAR: Mounted on aircraft, airborne LiDAR covers large areas swiftly. This makes it ideal for topographic mapping and forestry management. It further bifurcates into topographic and bathymetric LiDAR, as discussed earlier. Terrestrial LiDAR: Terrestrial LiDAR systems are stationed on the ground and are either static or mobile. These systems excel in detailed, high-accuracy modeling of structures, landscapes, roads, and archaeological sites. Piercing the Darkness: Is LiDAR Used at Night? Yes, LiDAR operates effectively both day and night. Unlike cameras that depend on light, LiDAR sensors emit their own light pulses. This makes them capable of working in complete darkness. Also, this trait makes LiDAR a cornerstone technology in applications that require round-the-clock operation. This can be helpful for autonomous vehicles and 24/7 surveillance systems. Envisioning the Future Uses of LiDAR As LiDAR technology continues to advance and become more accessible, its potential uses expand. In medicine, LiDAR could enable precise patient tracking and real-time monitoring for surgeries and treatments. In retail, LiDAR could streamline inventory management and facilitate autonomous checkouts. In the realm of virtual and augmented reality, high-precision LiDAR sensors could aid in creating hyper-realistic, immersive environments. As we move further into the future, we can expect LiDAR to be a lynchpin in the development of smart cities. Its capacity for creating accurate 3D models of urban environments can contribute significantly to urban planning. The technology can also be used for infrastructure management and environmental monitoring. Supervised Vs Unsupervised Machine Learning Summary LiDAR technology, with its distinctive ability to capture the world, is an indomitable force across diverse sectors. It can be used to illuminate unseen features beneath dense forest canopies and deep waters as well as for guiding the vehicles of the future. As technology continues to evolve and become more widely adopted, there is no telling where its light will shine next. FAQs References
Enhance Customer Experience with Best Sentiment Analysis Model

We’ve witnessed the profound impact of sentiment analysis on shaping business trajectories. Understanding customer sentiment isn’t just advantageous—it’s imperative in today’s hyper-connected era. With myriad models at our disposal, pinpointing the ‘best’ can be the difference between merely hearing and truly understanding your audience. This blog post will guide you towards the finest sentiment analysis models poised to elevate your customer experience to unprecedented heights. So, gear up for a deep dive into the transformative realm of sentiment analysis. And let’s decode emotions, together!Multiplied Productivity: How AI is Transforming the Future Understanding Sentiment Analysis Sentiment analysis (also known as opinion mining) aims to extract subjective information from text. It tries to determine whether the sentiment expressed is positive, negative, or neutral. It also provides more nuanced insight, determining the intensity of the sentiment or detecting more complex emotions. Best Language Model for Sentiment Analysis Several language models have been effectively used for sentiment analysis. Among the most successful is BERT (Bidirectional Encoder Representations from Transformers), a pre-trained model. BERT is developed by Google and has a unique architecture. It has the ability to understand the context from both directions (left and right of a word). This is the unique feature that makes BERT an exceptionally powerful modell for sentiment analysis.What Are Transformers in AI? | Large Language Models (ChatGPT) Explained Sentiment Analysis and Deep Learning Deep Learning has revolutionized the field of sentiment analysis. Models such as Long Short-Term Memory (LSTM) and Convolutional Neural Networks (CNN) have delivered impressive results. LSTM: As a variant of Recurrent Neural Networks (RNN), LSTM is excellent at learning from sequences of data. This makes it suitable for sentiment analysis tasks where the sentiment expressed can depend on the sequence of words. CNN: Originally designed for image processing, CNNs have also proven their worth in sentiment analysis. CNNs are good at detecting local patterns or features in data, such as words or phrases indicating sentiment in a text. The Emergence of Transformer Models Transformers, including models like BERT, GPT (Generative Pretrained Transformer), and RoBERTa, have quickly become the go-to models. They are often commonly used for many NLP tasks, including sentiment analysis. They leverage self-attention mechanisms and overcome the shortcomings of RNNs. For example, they are useful for difficulty handling long sequences, leading to improved accuracy. BERT for Sentiment Analysis BERT stands out due to its bidirectional nature. This is a model which can understand the context of a word based on all the other words in the sentence. This bidirectionality results in a nuanced understanding of the text, leading to highly accurate sentiment analysis. VADER Sentiment Analysis VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon-based sentiment analysis model. It’s specifically designed for social media sentiment analysis and works well with texts that contain slang. Its uniqueness lies in its ability to work with emoticons. VADER, although simpler than deep learning models, offers high speed and reasonable accuracy for specific use cases. Pre-Trained Sentiment Analysis Models Pre-trained models like BERT, RoBERTa, and DistilBERT have been trained on massive datasets. This has helped them learn a broad understanding of language in the process. They can be fine-tuned for specific tasks like sentiment analysis, significantly reducing training time and computational resources. Model Accuracy in Sentiment Analysis The “best” model often boils down to the one that provides the highest accuracy for your specific task. Transformer models like BERT often achieve the highest accuracy rates on benchmark sentiment analysis tasks. However, accuracy depends on various factors and cannot be determined based on one aspect. Other factors include the quality of your data, the complexity of the sentiment you’re trying to detect. It also depends on how well the model has been fine-tuned for the task. The Latest Models for Sentiment Analysis The latest models for sentiment analysis continue to evolve, with transformers leading the way. XLNet, a transformer model that outperforms BERT on several benchmarks. It is leveraging the best of both autoregressive and autoencoding methodologies to achieve excellent results. Another recent model is ALBERT (A Lite BERT), which is an optimized version of BERT. This is a model that delivers comparable performance but is much smaller and faster. In recent years, pre-trained models have also proven to be game-changers. They are offering high accuracy levels without the need for massive computational resources. However, as the field of sentiment analysis continues to evolve, so too will the models. The key is to stay updated with the latest advancements and understand the capabilities and limitations of each model to choose the one that best suits your needs. Conclusion In sentiment analysis, there is no one-size-fits-all model. The choice of the model depends on your specific requirements, including the nature of the data and the resources available. Also, you must not ignore the complexity of the sentiments you’re trying to analyze. Models like BERT, LSTM, and VADER all have their strengths and are the best choice under the right circumstances. FAQs References
Best Dataset For Machine Learning in 2023

Machine learning is a rapidly growing field that has revolutionized the way we interact with technology. It has enabled us to build intelligent systems that can learn from data and make predictions or decisions based on that data. However, building a machine learning model requires a large amount of data to train and test the model. In this article, we will explore the best dataset for machine learning that can help you build better models. What is Machine Learning? Machine learning is a subset of artificial intelligence that involves building systems that can learn from data. It involves training a model on a dataset and then using that model to make predictions or decisions based on new data. Machine learning has a wide range of applications, from image recognition to natural language processing. The Importance of Datasets in Machine Learning Datasets are a crucial component of machine learning. They provide the raw material that machine learning models use to learn and make predictions. Without high-quality datasets, machine learning models would not be able to learn effectively, and their predictions would be inaccurate. Top 15 Datasets for Machine Learning In this section, we will explore the top 15 datasets for machine learning that are publicly available. 1. MNIST Dataset The MNIST dataset is a classic dataset that is often used to benchmark machine learning algorithms. It contains a large number of handwritten digits that have been labeled with their corresponding values. The dataset is widely used for image recognition tasks and is an excellent resource for building models that can recognize handwritten digits. 2. CIFAR-10 Dataset The CIFAR-10 dataset is another classic dataset that is often used to benchmark machine learning algorithms. It contains 60,000 32×32 color images in 10 different classes, such as airplanes, cars, and cats. The dataset is widely used for image classification tasks and is an excellent resource for building models that can recognize different objects in images. 3. Iris Dataset The Iris dataset is a small but popular dataset that contains information on the sepal length, sepal width, petal length, and petal width of three different species of iris flowers. The dataset is often used for classification tasks and is an excellent resource for building models that can classify different types of flowers based on their physical characteristics. 4. Boston Housing Dataset The Boston Housing dataset is a dataset that contains information on housing prices in the Boston area. It includes data on factors such as crime rate, average number of rooms per dwelling, and accessibility to highways. The dataset is often used for regression tasks and is an excellent resource for building models that can predict housing prices based on various factors. 5. Wine Quality Dataset The Wine Quality dataset contains information on the physicochemical properties of different types of wine, as well as their quality ratings. The dataset is often used for classification tasks and is an excellent resource for building models that can predict the quality of wine based on its properties. 6. Breast Cancer Wisconsin (Diagnostic) Dataset The Breast Cancer Wisconsin (Diagnostic) dataset contains information on the characteristics of breast cancer cells, as well as their diagnosis (benign or malignant). The dataset is often used for classification tasks and is an excellent resource for building models that can predict whether a breast cancer cell is benign or malignant based on its characteristics. 7. Adult Census Income Dataset The Adult Census Income dataset contains information on the demographic and employment characteristics of individuals, as well as their income levels. The dataset is often used for classification tasks and is an excellent resource for building models that can predict whether an individual’s income is above or below a certain threshold based on their characteristics. 8. Yelp Dataset The Yelp dataset contains information on user reviews of businesses, as well as information on the businesses themselves. The dataset is often used for natural language processing tasks and is an excellent resource for building models that can analyze user reviews and predict the sentiment of those reviews. 9. ImageNet Dataset The ImageNet dataset is a massive collection of labeled images that is often used for image recognition tasks. It contains over 14 million images in more than 20,000 categories, making it an excellent resource for building models that can recognize a wide range of objects in images. 10. Stanford Dogs Dataset The Stanford Dogs dataset contains images of 120 different breeds of dogs, with each breed having around 100 images. The dataset is often used for image recognition tasks and is an excellent resource for building models that can recognize different breeds of dogs. 11. Fashion-MNIST Dataset The Fashion-MNIST dataset is a dataset that contains images of different types of clothing items, such as shirts, pants, and shoes. The dataset is often used for image recognition tasks and is an excellent resource for building models that can recognize different types of clothing items. 12. Open Images Dataset The Open Images dataset is a large collection of images that have been annotated with object detection bounding boxes and segmentation masks. It contains over 9 million images in more than 600 categories, making it an excellent resource for building models that can detect and segment objects in images. 13. COCO Dataset The COCO (Common Objects in Context) dataset is another large collection of images that have been annotated with object detection bounding boxes and segmentation masks. It contains over 330,000 images in 80 different object categories, making it an excellent resource for building models that can detect and segment objects in images. 14. YouTube-8M Dataset The YouTube-8M dataset is a large collection of videos that have been annotated with labels for different objects and scenes. It contains over 8 million videos in more than 4800 categories, making it an excellent resource for building models that can classify videos based on their content. 15. Reddit Dataset The Reddit dataset contains information on user comments and posts on the popular social media platform Reddit. The dataset is often used