
10 Best Practices for Microservices Architecture

As software development continues to evolve, microservices architecture has emerged as a popular approach for building complex applications. By breaking down large applications into smaller, independent services, microservices architecture offers greater flexibility, scalability, and resilience. However, designing and implementing a microservices architecture can be challenging, and there are many best practices to consider. In this article, we will explore some of the key best practices for microservices architecture, including domain-driven design, containerization, continuous integration and delivery, and more. Join us as we dive into the world of microservices and discover how to build better software. What are Microservices Architecture? Microservices architecture is a software development approach where a large application is broken down into smaller, independent services that can be developed, deployed, and scaled independently. Each microservice is designed to perform a specific business function and communicates with other microservices through APIs. This approach allows for greater flexibility, scalability, and resilience in software development. Kaggle vs Jupyter: Which One Suits Your Data Science Needs 10 Best Practices for Microservices 1. Domain-driven design: Domain-driven design is a software development approach that emphasizes the importance of understanding the business domain in which the software operates. By designing microservices around specific business domains, you can ensure that each microservice is focused on a specific business function and can be developed, deployed, and scaled independently. This approach also helps to reduce the complexity of the overall system, making it easier to manage and maintain. 2. Containerization: Containerization tools like Docker allow you to package and deploy microservices independently, without worrying about dependencies or conflicts with other services. This makes it easier to manage and scale microservices in a distributed environment. Containerization also provides a consistent environment for each microservice, which helps to reduce the risk of errors or bugs in production. 3. API Gateway: An API Gateway acts as a single entry point for all requests to your microservices. It manages and routes requests to the appropriate microservices, and can also handle tasks like authentication, rate limiting, and caching. This approach helps to simplify the overall architecture of your system, making it easier to manage and scale. 4. Service Registry and Discovery: A service registry and discovery tool like Consul or Eureka allows you to manage and discover microservices in a distributed environment. This makes it easier to scale and manage microservices, and ensures that each service can find and communicate with other services. Service registry and discovery also helps to reduce the complexity of the overall system, making it easier to manage and maintain. 5. Continuous Integration and Delivery: A CI/CD pipeline automates the build, test, and deployment of microservices. This ensures that each microservice is tested and deployed quickly and reliably, and reduces the risk of errors or bugs in production. Continuous integration and delivery also helps to improve the overall quality of your software, making it more reliable and easier to maintain. Datacamp vs Codecademy: Which Platform is Right for You? 6. Decentralized Data Management: Decentralized data management ensures that each microservice has its own data store, rather than sharing a single database. This makes it easier to manage and scale microservices independently, and reduces the risk of data conflicts or inconsistencies. Decentralized data management also helps to improve the overall performance of your system, making it faster and more responsive. 7. Fault Tolerance: Designing microservices to be fault-tolerant and resilient to failures is essential in a distributed environment. This involves using techniques like circuit breakers, retries, and timeouts to ensure that microservices can handle failures gracefully. 8. Security: Implementing security measures like authentication and authorization is essential to protect microservices from unauthorized access. This involves using techniques like OAuth, JWT, and SSL/TLS to secure microservices and their APIs. 9. Monitoring and Logging: Monitoring and logging tools like Prometheus and ELK allow you to track the performance and behavior of microservices in real-time. This makes it easier to identify and troubleshoot issues, and ensures that your microservices are performing optimally. 10. Team Organization: Organizing development teams around microservices ensures that each team is responsible for a specific microservice. This makes it easier to manage and scale microservices independently, and ensures that each team has the necessary skills and expertise to develop and execute the program. Final Thoughts! In conclusion, microservices architecture offers a flexible, scalable, and resilient approach to software development. By following best practices like domain-driven design, containerization, API Gateway, service registry and discovery, continuous integration and delivery, decentralized data management, fault tolerance, security, monitoring and logging, and team organization, you can design and implement a microservices architecture that meets the needs of your business. These best practices help to reduce the complexity of the overall system, improve the quality and performance of your software, and make it easier to manage and maintain. With the right approach and tools, microservices architecture can help you build software that is more reliable, efficient, and responsive.
Best API Gateway – How They Help Businesses?
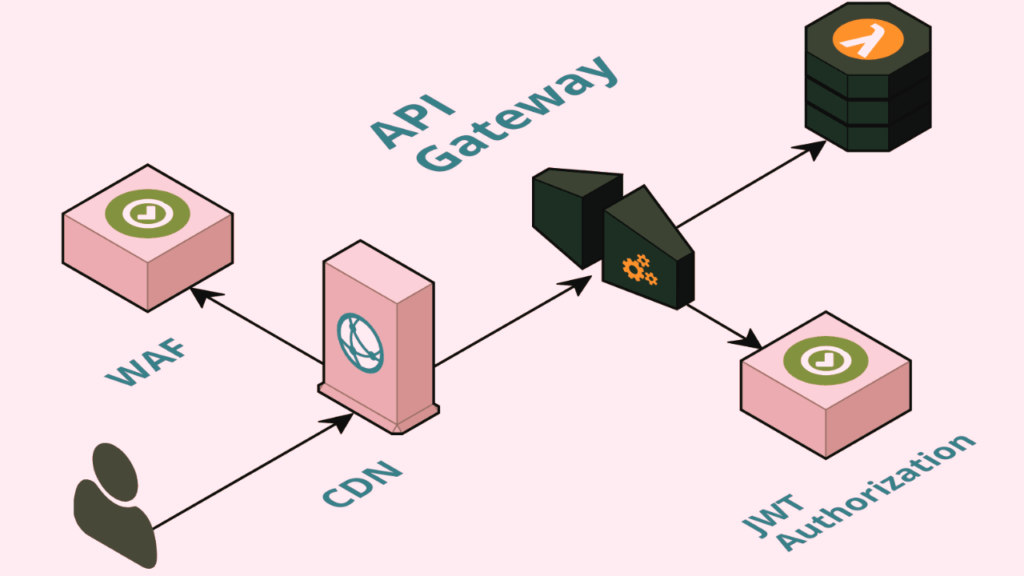
API gateways are a critical component of modern application architectures, providing a centralized point of control for managing and securing APIs. With so many options available, choosing the best API gateway for your organization can be a daunting task. In this article, we’ll take a closer look at some of the best API gateway solutions on the market today, comparing their features, performance, and ease of use. Whether you’re a developer looking to build and manage APIs, or an IT leader looking to streamline your organization’s API management processes, this article will help you make an informed decision about which API gateway is right for you.Amazon’s ARMBench Dataset: A Comprehensive Solution for Robotic Manipulation in Warehouses What is Best API Gateway? An API Gateway is a server or service that acts as an API’s entry point, providing a centralized point of control for managing and routing requests to various microservices or backend services. It serves as an intermediary layer between clients (such as mobile apps or web applications) and the underlying services that fulfill those requests. Here are some key aspects of an API Gateway: 1: Request Routing: An API Gateway routes incoming requests from clients to the appropriate microservices or backend services based on predefined rules or configurations. It acts as a traffic cop, ensuring that each request reaches the correct destination. 2: Load Balancing: In many cases, an API Gateway includes load balancing capabilities, distributing incoming requests evenly across multiple instances of a service to ensure optimal performance and availability. 3: Security: API Gateways often provide security features such as authentication, authorization, and encryption. They can enforce access control policies, verify user identities, and protect against common security threats like SQL injection and cross-site scripting (XSS) attacks. 4: Request Transformation: API Gateways can modify or transform incoming requests and responses. This includes translating between different data formats (e.g., JSON to XML), aggregating data from multiple sources, or adding metadata to requests for analytics. 5: Logging and Monitoring: They offer logging and monitoring capabilities, allowing administrators to track request traffic, monitor performance, and troubleshoot issues. This is essential for maintaining the health and reliability of APIs. 6: Rate Limiting: API Gateways can implement rate limiting policies to prevent abuse or overuse of API resources. This helps ensure fair and efficient resource allocation. 7: Caching: Some API Gateways support caching responses to reduce the load on backend services and improve response times. Cached data can be served for identical requests without hitting the backend again. 8: API Composition: In cases where an API needs to fetch data from multiple microservices or data sources, the API Gateway can aggregate the data and present it as a single response, simplifying client-side integration. 9: Version Management: They can handle API versioning, allowing developers to make changes to APIs without breaking existing clients. Different API versions can coexist, and clients can specify which version they want to use. API Gateways play a crucial role in modern microservices architectures and are particularly valuable when dealing with complex systems comprising multiple services. They streamline the management, security, and scalability of APIs, making it easier for developers to build, deploy, and maintain robust and efficient applications. API Analytics Help Businesses Improve Their Digital Strategies in Different Ways API analytics can provide businesses with valuable insights into how their APIs are being used, which can help them improve their digital strategies in several ways. Here are some examples: 1: Identify popular use cases: By analyzing API traffic data, businesses can identify which use cases are most popular among their users. This information can help them prioritize development efforts and focus on features that are in high demand.What is ControlNet? An Overview of the Industrial Control Network 2: Optimize API performance: API analytics can provide detailed information about API performance, such as response times and error rates. By monitoring these metrics, businesses can identify bottlenecks and other issues that may be affecting the user experience. They can then take steps to optimize API performance and improve the overall user experience. 3: Improve developer engagement: API analytics can help businesses understand how developers are using their APIs and what challenges they may be facing. By addressing these challenges and providing developers with the tools and resources they need, businesses can improve developer engagement and build a stronger developer community. 4: Measure ROI: By tracking API usage and other metrics, businesses can measure the ROI of their API program. They can identify which APIs are generating the most value and which may need to be optimized or retired. This information can help businesses make data-driven decisions about their API program and allocate resources more effectively. Overall, API analytics can provide businesses with a wealth of information about how their APIs are being used and how they can be improved. By leveraging this data, businesses can build better digital strategies and stay ahead of the competition. Some Common Challenges in API Management and How Can They Be Addressed? API management can be a complex and challenging process, and there are several common challenges that businesses may face. Here are some examples of these challenges and how they can be addressed: 1: Security: APIs can be vulnerable to security threats such as hacking, data breaches, and denial-of-service attacks. To address these challenges, businesses should implement strong authentication and authorization mechanisms, use encryption to protect data in transit, and monitor API traffic for suspicious activity. 2: Scalability: As API usage grows, businesses may struggle to scale their infrastructure to meet demand. To address this challenge, businesses can use cloud-based infrastructure and auto-scaling technologies to ensure that their APIs can handle spikes in traffic. 3: Developer engagement: Building a strong developer community is essential for the success of an API program, but it can be challenging to engage developers and keep them interested. To address this challenge, businesses should provide clear documentation and examples, offer developer support and training, and create a developer portal that makes it easy for developers to discover and use
Best Serverless Frameworks – An Ultimate Guide!
Are you looking for a way to simplify the deployment of your serverless applications? Look no further! In this blog, we’ve compiled a list of the best serverless frameworks on the market today. Whether you’re a seasoned developer or just starting out, our list includes frameworks that are flexible, customizable, and can deploy the same code to many different serverless providers. From the popular Serverless Framework to the up-and-coming OpenFaaS, we’ve got you covered. So, sit back, relax, and read on to discover the best serverless frameworks for your next project. What Are Serverless Frameworks? The Serverless Framework is a free, open-source framework that was launched in 2015. It is primarily aimed at deployment on the AWS platform, but it can deploy the same code to many different serverless providers, including Google Cloud and Microsoft Azure. The framework can make the deployment of serverless applications easier by creating the cloud infrastructure dependencies described in a single configuration file. This infrastructure can be treated as code, which makes scaling easier and faster to implement. The Serverless Framework adds an abstraction layer on top of the serverless platforms, which is a step towards simplifying the deployment process regardless of the underlying platform and a move towards a more standardized way of creating serverless applications in the future. When deploying a serverless application, it is possible to develop, deploy, test, secure, and monitor the application in the Serverless Framework Dashboard. The Serverless Framework is designed to be flexible and customizable, with a plugin architecture that allows developers to extend the framework’s functionality. The framework also includes a command-line interface (CLI) that provides a set of commands for creating, deploying, and managing serverless applications. How Serverless Frameworks Are Aiding Today’s Software Industry? Here are some subheadings that answer “How Serverless Frameworks Are Aiding Today’s Software Industry: 1. Simplifying Deployment The Serverless Framework automates the configuration of cloud infrastructure dependencies, making deployment of serverless applications easier and faster. The framework’s plugin architecture allows developers to extend its functionality, making it more customizable and flexible. Datacamp vs Codecademy: Which Platform is Right for You? 2. Standardizing Serverless Development The Serverless Framework adds an abstraction layer on top of serverless platforms, making it easier to deploy applications regardless of the underlying platform. This move towards standardization is a step towards a more consistent way of creating serverless applications in the future. 3. Cost-Effective Scaling Serverless architectures allow for automatic scaling, which means that resources are only used when needed, making it more cost effective than traditional server architectures. The Serverless Framework makes scaling easier and faster to implement, allowing developers to focus on building their applications rather than worrying about infrastructure. 4. Increased Efficiency Serverless architectures allow developers to focus on building their applications rather than managing infrastructure, which increases efficiency and productivity. The Serverless Framework’s command-line interface (CLI) provides a set of commands for creating, deploying, and managing serverless applications, making it easier to manage and maintain applications. Some of the Best Serverless Frameworks 1: Serverless Framework The Serverless Framework is one of the most popular serverless frameworks available today. It supports multiple cloud providers, including AWS, Azure, and Google Cloud Platform. It provides a plugin architecture that allows developers to extend its functionality and customize their deployments. 2. AWS SAM AWS SAM (Serverless Application Model) is a framework for building serverless applications on AWS. It provides a simplified way to define the Amazon API Gateway APIs, AWS Lambda functions, and Amazon DynamoDB tables needed by your serverless application. 3. OpenFaaS OpenFaaS (Functions as a Service) is an open-source serverless framework that allows developers to build and deploy functions to Kubernetes. It supports multiple languages, including Node.js, Python, and Go. 4. Kubeless Kubeless is another open-source serverless framework that allows developers to deploy functions to Kubernetes. It supports multiple languages, including Python, Node.js, and Ruby. 5. Fn Project The Fn Project is an open-source serverless framework that allows developers to build and deploy functions to any cloud or on-premises environment. It supports multiple languages, including Java, Go, and Python. What is DataRobot? 6. IronFunctions IronFunctions is an open-source serverless framework that allows developers to build and deploy functions to any cloud or on-premises environment. It supports multiple languages, including Node.js, Python, and Go. 7. Nuclio Nuclio is an open-source serverless framework that allows developers to build and deploy functions to Kubernetes. It supports multiple languages, including Python, Node.js, and Go. 8. Zeit Now Zeit Now is a serverless framework that allows developers to deploy serverless functions and applications to the cloud. It supports multiple languages, including Node.js, Python, and Go. 9. Google Cloud Functions Google Cloud Functions is a serverless framework that allows developers to build and deploy functions to the Google Cloud Platform. It supports multiple languages, including Node.js, Python, and Go. 10. Azure Functions Azure Functions is a serverless framework that allows developers to build and deploy functions to Azure. – It supports multiple languages, including Node.js, Python, and C#. Final Thoughts! In addition to the Serverless Framework, there are many other great serverless frameworks available today, each with its own unique features and benefits. From AWS SAM to OpenFaaS, Kubeless, and more, these frameworks are helping developers simplify deployment, standardize serverless development, and increase efficiency. Whether you’re a seasoned developer or just starting out, these frameworks can help you build and deploy serverless applications faster and more easily than ever before. So, why not give them a try and see how they can help you take your serverless development to the next level?
Serverless Vs Containers – Which One to Choose and Why?

As cloud computing continues to evolve, two of the most popular technologies that have emerged are serverless computing and containers. Both serverless and containers offer unique benefits and have their own set of use cases. However, choosing between the two can be a daunting task for developers and businesses alike. In this blog, we will explore the differences and similarities between serverless vs containers, and help you make an informed decision on which technology to choose for your next project. Whether you are a seasoned developer or just starting out, this blog will provide you with the insights you need to make the right choice for your application. So, let’s dive in and explore the world of serverless and containers! What is Serverless? Serverless computing is a form of cloud computing in which the cloud provider manages the server and resources needed to maintain the server. It was popularized by AWS Lambda, Amazon’s serverless offering. Every action performed on a serverless platform is independent, which enables independent management and scaling. Thus, serverless environments are highly compatible with microservices architectures as they provide the isolation and scaling properties that enable microservices. As microservices become the norm, more IT teams may turn to serverless computing as a solution. What are Containers? Containers are software packages that can house an application along with the tools and settings necessary to run the application. This grants developers the ability to build applications that can be easily shifted between server environments without disrupting its functionality. Containers are designed to function in isolation and to have the minimum resources needed to run an application. In essence, they operate similarly to a shipping container – multiple objects are packed into one shipping container for ease of transportation from one facility to another, a more efficient method than moving each individual object from one location to the next Serverless Vs Containers – Differences Here are five differences between serverless and containers: 1: Management Flexibility: With containers, the user can have control of the container system, including how to allocate and manage resources. Although this comes with an added level of complexity, it gives users more flexibility in managing their applications. When going serverless, the user has to rely on how the vendor manages its servers and resources. 2. Code Run-time: Containers allow for longer code runtimes, while serverless platforms will limit the amount of time a function can be deployed. AWS Lambda, for example, imposes a 900-second limit after which the function is aborted. 3. Vendor Flexibility: Users can take advantage of offerings from different vendors when running containers, avoiding the risk of vendor lock-in. Conversely, serverless computing restricts the user to a single serverless platform. 4. Security: Serverless functions are difficult to monitor, have a larger attack surface due to the increased number of events that can call the function, and rely on more third-party libraries, which enhance functionalities but are also vulnerable to attacks and require monitoring. 5. Application Use-case Variety: Containers can support a wider variety of applications. Containers can handle stateful applications as platforms like Pivotal Container Service and Red Hat OpenShift support both stateless and stateful applications, providing persistent storage for containers such as databases for storing container state information. Developers are also able to utilize external storage tools which are mapped to the container and manage data outside of the container, allowing data to exist after the container terminates. Serverless Vs Containers – Similarities Here are five similarities between serverless and containers: 1. Scalability: Both serverless and containers are highly scalable. Serverless computing is designed to scale automatically by the vendor, while containers can be scaled horizontally by adding more containers to the cluster. What is DataRobot? 2. Microservices: Both serverless and containers are highly compatible with microservices architectures. Serverless environments are highly compatible with microservices architectures as they provide the isolation and scaling properties that enable microservices. Containers are designed to function in isolation and to have the minimum resources needed to run an application, making them ideal for microservices. 3. Stateless Applications: Both serverless and containers are best suited for stateless applications since they do not have persistent storage and shut down after the applications are run. 4. Cost-Effective: Both serverless and containers can be cost-effective. Serverless computing has a pay-as-you-go pricing structure that can help reduce costs, while containers can be run on commodity hardware, reducing the need for expensive infrastructure. Kaggle vs Jupyter: Which One Suits Your Data Science Needs 5. Portability: Both serverless and containers are highly portable. Containers are designed to be easily shifted between server environments without disrupting their functionality, while serverless functions are independent, which enables independent management and scaling. Serverless Vs Containers – What to Choose? The decision to use serverless or containers will depend on the specific needs of the application and the preferences of the development team. Serverless computing is more appropriate for more specialized use-cases and event-driven applications, whereas containers are better suited for general use-cases and purposes. If the application requires longer code runtimes, vendor flexibility, or more control over the management of resources, containers may be the better choice. On the other hand, if the application is event-driven, requires automatic scaling, or has unpredictable traffic patterns, serverless computing may be the better choice. In some cases, it may be beneficial to use both serverless and containers in combination. For example, a serverless function could be used to handle event-driven tasks, while a container could be used to run a stateful application. Ultimately, the choice between serverless and containers will depend on the specific needs of the application and the preferences of the development team. Final Thoughts! We hope that this blog has helped you gain a better understanding of the differences and similarities between serverless computing and containers. While both technologies have their own unique benefits, the choice between the two ultimately depends on the specific needs of your application and the preferences of your development team. As cloud computing continues to evolve, it’s important to stay up-to-date
Microservices Vs API – Differences, Similarities, and More!

Are you ready to take your software development skills to the next level? Look no further than the world of microservices vs APIs. These two approaches to building software have taken the tech industry by storm, and for good reason. In this blog, we’ll explore the exciting world of microservices and APIs, and help you understand the key differences between them. From the benefits of containerization to the power of RESTful APIs, we’ll cover everything you need to know to make informed decisions about your software architecture. So buckle up and get ready to join the revolution. Kaggle vs Jupyter: Which One Suits Your Data Science Needs . What is Microservices Architecture? Microservices architecture is an approach to building software that emphasizes the creation of small, independent services that work together to form a larger application. Each service is designed to perform a specific function, and communicates with other services through APIs. This approach allows for greater flexibility and scalability, as each service can be developed, deployed, and scaled independently of the others. Microservices architecture is often contrasted with monolithic architecture, in which all of the application’s functionality is contained within a single codebase. Uses of Microservices Microservices architecture has a number of potential benefits for software development, including: 1: Scalability: Because each microservice is designed to perform a specific function, it can be scaled independently of the others. This allows for greater flexibility and efficiency in managing resources. 2. Resilience: Microservices are designed to be fault-tolerant, meaning that if one service fails, it does not bring down the entire application. This can help to ensure that the application remains available and responsive even in the face of failures. 3. Agility: Microservices architecture allows for greater agility in software development, as each service can be developed, tested, and deployed independently of the others. This can help to speed up the development process and reduce time-to-market. RASP vs WAF: Which is the Better Security Solution? 4. Maintainability: Because each microservice is relatively small and focused, it can be easier to maintain and update than a monolithic application. This can help to reduce the risk of introducing bugs or other issues when making changes to the codebase. 5. Technology diversity: Microservices architecture allows for greater flexibility in choosing the technologies used for each service. This can help to ensure that each service is using the best technology for its specific function, rather than being limited by the technology choices made for the entire application. What is an API? An API, or application programming interface, is a set of protocols, routines, and tools for building software applications. APIs define how different software components should interact with each other, and provide a way for developers to access the functionality of another application or service. APIs are often used to enable communication between different microservices in a microservices architecture. They can also be used to allow third-party developers to access the functionality of a web application or service, such as retrieving data or performing specific actions. APIs typically use a standardized format for communication, such as REST (Representational State Transfer), SOAP (Simple Object Access Protocol), or GraphQL. Microservices Vs Api – What’s their Purpose? microservices and APIs serve different purposes, but they are often used together in modern software development. Microservices architecture is an approach to building software that emphasizes the creation of small, independent services that work together to form a larger application. Each service is designed to perform a specific function, and communicates with other services through APIs. APIs, on the other hand, are a set of protocols, routines, and tools for building software applications. APIs define how different software components should interact with each other, and provide a way for developers to access the functionality of another application or service. APIs are often used to enable communication between different microservices in a microservices architecture. In other words, microservices are the building blocks of an application, while APIs are the communication tools that allow those building blocks to work together. Microservices Vs Api – Some Similarities Here are five similarities between microservices and APIs: 1. Both microservices and APIs are used in modern software development to create scalable, flexible, and modular applications. 2. Both microservices and APIs are designed to be loosely coupled, meaning that changes to one service or component should not affect the others. 3. Both microservices and APIs are often used in cloud-based applications, where services are distributed across multiple servers or data centers. 4. Both microservices and APIs can be used to enable communication between different parts of an application, or between different applications altogether 5. Both microservices and APIs can be used to improve the overall performance, reliability, and maintainability of an application. Microservices Vs Api – Some Differences Here are five differences between microservices and APIs: 1. Microservices are a way of designing and building software applications, while APIs are a way of enabling communication between different software components. 2. Microservices are typically small, independent services that are designed to perform a specific function, while APIs can be used to access the functionality of an entire application or service. 3. Microservices are often used in cloud-based applications, where services are distributed across multiple servers or data centers, while APIs can be used in any type of software application. 4. Microservices are designed to be loosely coupled, meaning that changes to one service should not affect the others, while APIs can be tightly coupled, meaning that changes to one component can have a significant impact on the others. 5. Microservices are often managed and deployed independently, while APIs are typically managed and deployed as part of a larger application or service. Bottom Line: While microservices and APIs share some similarities, they serve different purposes in modern software development. Microservices are the building blocks of an application, while APIs are the communication tools that allow those building blocks to work together. Understanding the differences between microservices and APIs is crucial for developers who want to create scalable, flexible,
Synapse Vs Databricks – Everything You Need to Know!

In this blog, we will be Synapse vs Databricks, two cloud-based data platforms that provide scalable and flexible environments for big data processing and analytics. We will explore the similarities and differences between these two platforms, and provide insights to help you choose the right one for your organization. But wait, there’s more! We’ll also provide insights into the broader world of cloud-based data platforms and offer tips for evaluating your options and choosing the best solution for your organization. So buckle up and get ready to explore the exciting world of Synapse vs Databricks! What is Synapse? Synapse is a cloud-based analytics service offered by Microsoft Azure that combines big data and data warehousing. It allows users to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. Synapse also provides a unified experience for data engineers, data scientists, and business analysts to collaborate on big data and AI projects. Key Features of Synapse 1: Unified Analytics: Synapse provides a unified experience for big data and data warehousing. It allows users to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. Synapse also provides a unified workspace for data engineers, data scientists, and business analysts to collaborate on big data and AI projects. 2. Enterprise-grade Security: Synapse provides enterprise-grade security features to protect data and ensure compliance. It supports Azure Active Directory for authentication and authorization and provides role-based access control (RBAC) to manage access to resources. Synapse also supports data encryption at rest and in transit and provides auditing and monitoring capabilities to track data access and usage. 3. Intelligent Insights: Synapse provides intelligent insights to help users derive insights from big data. It supports built-in machine learning models for anomaly detection, classification, and regression, and provides integration with Azure Machine Learning for custom model training and deployment. Synapse also supports Power BI for data visualization and reporting and provides integration with Azure Data Factory for data integration and orchestration. What is Databricks? Databricks is a cloud-based data engineering tool for processing, transforming, and exploring large volumes of data to build machine learning models intuitively. It is a zero-management cloud platform built around Apache Spark clusters to provide an interactive workspace. Databricks enable data analysts, data scientists, and developers to extract value from big data efficiently. It also supports third-party applications such as AI and domain-specific tools for generating valuable insights. Large-scale enterprises utilize this platform for a broader spectrum to perform ETL, data warehousing, or data hoarding insights for internal users and external clients. Key Features of Databricks Some of the key features of Databricks are: 1: Cloud-based Data Engineering: Databricks is a cloud-based data engineering tool that provides a zero-management cloud platform built around Apache Spark clusters to provide an interactive workspace. It enables data analysts, data scientists, and developers to extract value from big data efficiently. Databricks supports three major cloud partners: AWS, Microsoft Azure, and Google Cloud. 2. Language Compatibility: Databricks supports multiple programming languages such as Python, R, Scala, and SQL. These languages are converted to Spark at the backend through API, allowing users to work in their preferred programming language. 3. Productivity and Collaboration: Databricks provides a collaborative workspace between data scientists, engineers, and business analysts. It allows interaction among multiple members, bringing novel ideas during the early stages of machine learning application life cycle. Additionally, version control of source code becomes a painless task as all involved users have access to ongoing projects. Kaggle vs Jupyter: Which One Suits Your Data Science Needs Synapse Vs Databricks – Some Differences Here are some differences between Synapse and Databricks: 1: Data Warehousing vs. Data Engineering: Synapse is primarily a data warehousing tool that provides a unified experience for big data and data warehousing. It allows users to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. On the other hand, Databricks is a cloud-based data engineering tool that provides a zero-management cloud platform built around Apache Spark clusters to provide an interactive workspace. It enables data analysts, data scientists, and developers to extract value from big data efficiently. 2. Language Compatibility: Databricks supports multiple programming languages such as Python, R, Scala, and SQL. These languages are converted to Spark at the backend through API, allowing users to work in their preferred programming language. Synapse, on the other hand, supports SQL and T-SQL for data querying and transformation. 3. Machine Learning Capabilities: Databricks provides built-in machine learning models for anomaly detection, classification, and regression, and provides integration with Azure Machine Learning for custom model training and deployment. Synapse, on the other hand, provides integration with Azure Machine Learning for custom model training and deployment, but does not provide built-in machine learning models. 4. Pricing Model: Databricks pricing is based on the number of virtual machines (VMs) used, while Synapse pricing is based on the amount of data processed. Databricks provides a free community edition, while Synapse does not have a free version. Synapse Vs Databricks – A few Similarities Here are some similarities between Synapse and Databricks: 1: Both are cloud-based: Both Synapse and Databricks are cloud-based data platforms that provide a scalable and flexible environment for big data processing and analytics. 2. Integration with Azure Services: Both Synapse and Databricks are integrated with other Azure services such as Azure Data Factory, Azure Data Lake Storage, and Azure Machine Learning. This integration allows users to build end-to-end data pipelines and machine learning workflows. What is v7 LABS? 3. Apache Spark: Both Synapse and Databricks are built on top of Apache Spark, an open-source big data processing engine. This allows users to leverage the power of Spark for data processing, analytics, and machine learning. 4. Collaboration: Both Synapse and Databricks provide a collaborative workspace between data scientists, engineers, and business analysts. They allow interaction among multiple members, bringing novel ideas during the early stages of machine learning application life cycle. Additionally, version control of source code becomes a painless task