As we delve deeper into the digital age, the amount of textual data we produce continues to grow at an unprecedented rate. This vast sea of data can be challenging to navigate, particularly when we need to extract specific pieces of information. This is where Named Entity Recognition (NER) comes into play and helps us.
NER isn’t just about detecting words; it’s about understanding context, pinpointing specific entities, and making sense of vast textual landscapes.
Named Entity Recognition is a powerful tool in the field of Natural Language Processing (NLP). It allows us to distill valuable insights from unstructured text. Now, let’s take a closer look at Named Entity Recognition and understand its true meaning.
What is Named Entity Recognition?
Named Entity Recognition (NER) is a sub-task of information extraction in NLP. It seeks to locate and classify named entities mentioned in unstructured text into predefined categories. Examples are person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Imagine reading a news article about a company’s financial performance and wanting to extract specific details. How can you extract details like the company name, its profits, and the fiscal quarter?
Well, NER is the process that enables this extraction, making it a valuable tool for many applications. It is useful for news aggregation and content recommendation to customer support and sentiment analysis.
What is the Objective of Named Entity Recognition?
The main objective of Named Entity Recognition is to extract structured information from unstructured text data. It aims to identify atomic elements in the text and categorize them into predefined classes of named entities. NER allows us to transform the raw text into a form that is easier to analyze. Easy understanding is a critical step in many NLP pipelines, including information extraction, question answering, and machine translation.
What is an example of a Named Entity?
A named entity can be any word or sequence of words that consistently refers to the same thing. Each named entity belongs to a predefined category.
For example, look at the sentence, “Apple Inc. reported profits of $58 billion in the third quarter of 2022”. Here, “Apple Inc.” is a named entity of the category “Organization” while “$58 billion” falls under the “Monetary” category. Whereas, at the end, the “third quarter of 2022” is a “Time” entity.
CES 2023 | When will robots take over the world?
What is the NER Model?
A NER model is a machine learning or deep learning model used to predict the named entities in text. It takes a sequence of words as input and labels each word with a tag that represents the category. NER models are typically trained on annotated corpora – large bodies of text in which named entities have been labeled by human annotators.
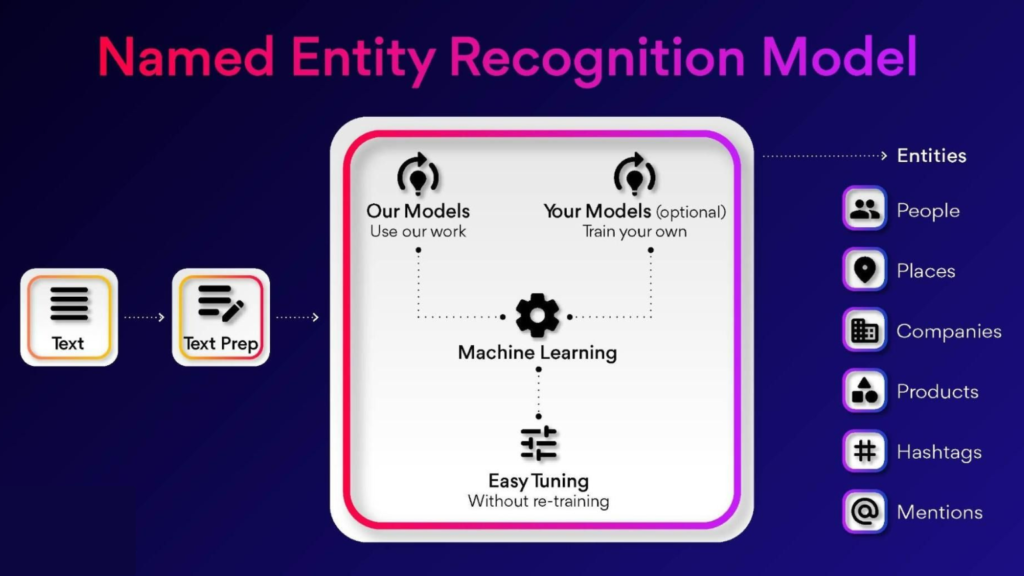
What are the Techniques of NER?
Named Entity Recognition is approached using various techniques. These techniques range from rule-based methods to machine learning and deep learning models.
Rule-Based Methods: These methods use handcrafted rules to identify named entities. For example, one might create a rule for any sequence of words starting with a capital letter. This can then be followed by a common business suffix like “Inc.” or “LLC” is an organization.
Machine Learning Methods: Machine learning models like Conditional Random Fields (CRFs), Support Vector Machines (SVMs), and Decision Trees can be trained to recognize named entities. They can do so based on features such as the word itself, its part of speech, its position in the sentence, and the words around it.
Deep Learning Methods: Deep learning models, particularly Recurrent Neural Networks (RNNs) and Transformer-based models like BERT (Bidirectional Encoder Representations from Transformers), have achieved state-of-the-art results on NER tasks. These models can capture complex patterns and dependencies in the text. This improves the accuracy of named entity recognition.
CES 2023 Robotics Innovation Awards | Best New Robot Ventures
What are 2 Common Techniques for Named Entity Recognition?
Two common techniques for NER are:
Conditional Random Fields (CRFs): CRFs are a popular machine-learning method for NER. They model the context in which a word appears to predict its named entity tag. In doing so, they take into account not just the individual word, but the tags of the surrounding words as well.
BERT-Based Models: BERT-based models have recently achieved top performance on NER tasks. BERT is a transformer-based model that uses a bidirectional training mechanism to understand the context of a word. It understands context in relation to all the other words in the sentence, rather than just the words before it or after it.
Conclusion
Named Entity Recognition is a crucial component of NLP, playing a pivotal role in understanding and organizing textual data. Through various techniques, NER models have become increasingly sophisticated, capable of identifying nuanced details. They can understand context within a sea of unstructured text. As technology continues to evolve, the importance and capabilities of Named Entity Recognition will undoubtedly grow.
What is Named Entity Recognition (NER)?
What is the main goal of Named Entity Recognition?
Can you provide an example of a named entity?
What is an NER model?
How does Named Entity Recognition work?
What are some techniques used in Named Entity Recognition?
What is the difference between rule-based and machine learning methods for NER?
How does BERT improve Named Entity Recognition?
How is Named Entity Recognition used in real-world applications?
Is Named Entity Recognition a solved problem in Natural Language Processing?
References
- https://www.sciencedirect.com/topics/computer-science/named-entity-recognition#:~:text=The%20goal%20of%20NER%20is,et%20al.%2C%202014).
- https://www.techtarget.com/whatis/definition/named-entity-recognition-NER
- https://www.mygreatlearning.com/blog/named-entity-recognition/
- https://www.geeksforgeeks.org/named-entity-recognition/