Machine learning has revolutionized the way we analyze and process data, especially in the field of document analysis. However, the effectiveness of machine learning algorithms depends on how well they are evaluated. In this article, we will explore the importance of evaluation metrics such as precision vs accuracy machine learning in document analysis.
MIT Technology Review 35under35 | Jonas Cleveland | A Robotics Entrepreneur’s Motivation in Johnny5
The Process of Document Analysis
Document analysis involves transforming printed documents into an electronic representation. This process involves several subtasks such as image processing, layout segmentation, structure recognition, and optical character recognition (OCR). One of the most important subtasks of document analysis is document categorization, which involves the automatic classification of documents into different types. This allows for workflow management, automatic routing or archiving of documents, and many other practical applications.
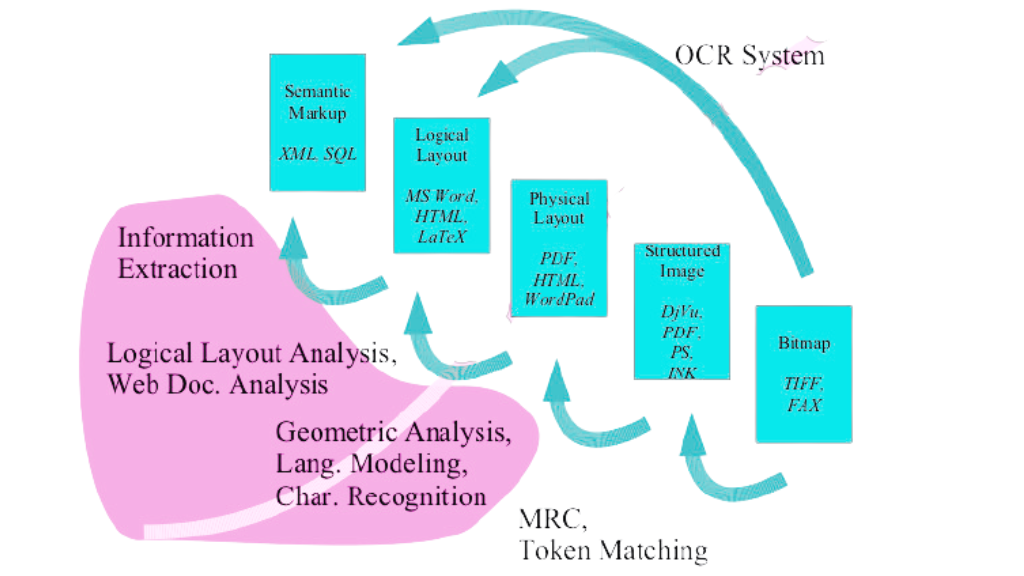
To evaluate the effectiveness of document analysis systems, we need to use appropriate evaluation metrics. In document categorization, for example, we are interested in stating something about the performance of a particular algorithm. We are also interested in comparing different document categorization algorithms by their effectiveness. The effectiveness of text retrieved systems is usually given by the well-known IR standard measures recall and precision.
Key Evaluation Metrics in Document Analysis
Recall, precision, and accuracy are commonly used evaluation metrics in document analysis. Recall measures the proportion of relevant documents that are retrieved by a system, while precision measures the proportion of retrieved documents that are relevant. Accuracy measures the proportion of correct classifications made by a system. These metrics are essential in determining the effectiveness of document analysis systems.
Statistical Reliability in Evaluation
However, it is important to note that the experimental evaluation on relatively small test sets – as is very common in document analysis – has to be taken with extreme care from a statistical point of view. In fact, it is surprising how weak statements derived from such evaluations are. Therefore, it is important to use appropriate statistical methods to ensure that the results obtained are reliable.
The effectiveness of machine learning algorithms in document analysis depends on how well they are evaluated.
Evaluation metrics such as recall, precision, and accuracy are essential in determining the effectiveness of document analysis systems. However, it is important to use appropriate statistical methods to ensure that the results obtained are reliable. By understanding the importance of evaluation metrics, we can improve the effectiveness of machine learning algorithms in document analysis.
Understanding Precision vs. Accuracy
Precision and accuracy are two evaluation metrics that are often used interchangeably in machine learning. However, they have different meanings and are used in different contexts. Precision measures the proportion of true positives among all positive predictions, while accuracy measures the proportion of correct predictions among all predictions. In other words, precision measures how many of the predicted positive cases are actually positive, while accuracy measures how many of all cases are correctly predicted.
Application Relevance
In document analysis, precision and accuracy are both important metrics for evaluating the effectiveness of machine learning algorithms. Precision is particularly important in applications where false positives can have serious consequences, such as in medical diagnosis or fraud detection. In these cases, it is more important to avoid false positives than to maximize the number of true positives. For example, in a medical diagnosis system, a false positive could lead to unnecessary treatment or surgery, which can be harmful to the patient.
On the other hand, accuracy is more important in applications where false negatives can have serious consequences, such as in security or safety-critical systems. In these cases, it is more important to avoid false negatives than to maximize the number of true positives. For example, in a security system, a false negative could allow unauthorized access to a secure area, which can be a serious security breach.
In document analysis, precision and accuracy are often used together to evaluate the effectiveness of machine learning algorithms. For example, in document categorization, we may be interested in maximizing both precision and accuracy. This means that we want to maximize the number of relevant documents that are retrieved (high recall), while minimizing the number of irrelevant documents that are retrieved (high precision). At the same time, we want to maximize the number of correct classifications made by the system (high accuracy).
Striking a Balance: Precision, Accuracy, and Their Trade-offs
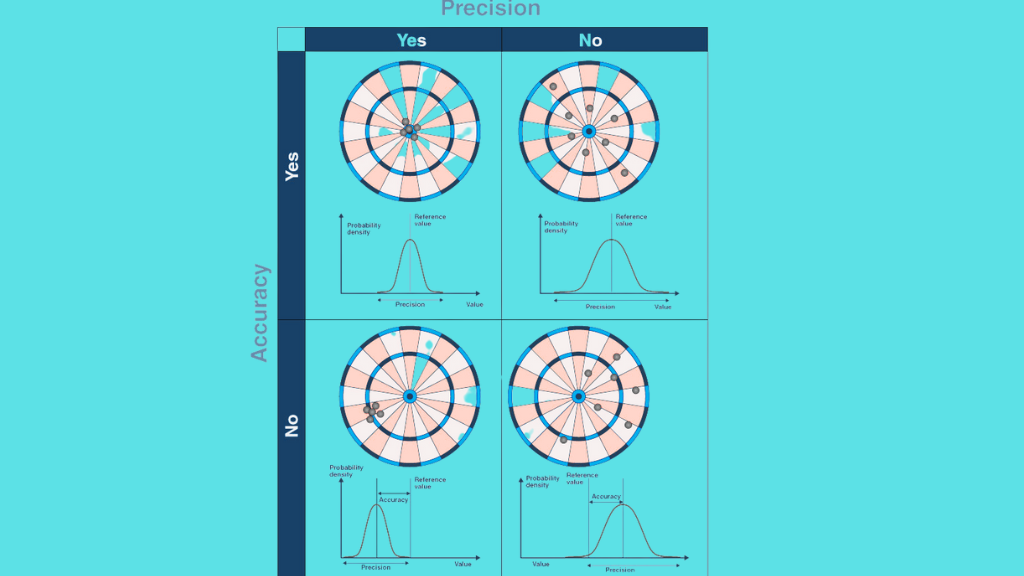
It is important to note that precision and accuracy are not always compatible metrics. In some cases, increasing precision may lead to a decrease in accuracy, and vice versa. For example, in a spam filter, increasing precision may require rejecting more emails as spam, which can lead to a decrease in accuracy if some legitimate emails are also rejected. Therefore, it is important to find a balance between precision and accuracy that is appropriate for the specific application.
Conclusion
In conclusion, precision and accuracy are important evaluation metrics in document analysis and machine learning in general. They measure different aspects of the effectiveness of machine learning algorithms and are used in different contexts. By understanding the differences between precision and accuracy and their appropriate use in different applications, we can improve the effectiveness of machine learning algorithms in document analysis and other fields.
FAQs
What’s the difference between precision and accuracy in machine learning?
Accuracy in machine learning measures the ratio of correct predictions to the total number of predictions. Whereas precision measures the proportion of correctly predicted positive observations to the total predicted positives. In other words, accuracy gives an overview of the model’s performance, while precision provides a measure of the model’s reliability by predicting a positive class.
What are the three types of precision?
The three most common types of precision are:
Precision as a classification metric: It measures the proportion of correctly predicted positive observations.
Precision in numerical computations: It refers to the degree of numerical detail that a computational process can handle.
Precision is a measure: It is a measurement of repeatability or reproducibility in fields like physics or engineering.
What is the role of recall in machine learning?
Recall, also known as sensitivity or true positive rate, measures the proportion of actual positives. It’s an important measure in scenarios where we want to minimize the number of false negatives. For example, in a medical diagnosis scenario, a high recall would mean that the model correctly identifies most of the positive cases.Thus, reducing the chance of missing a critical diagnosis.
What is the F1 score in machine learning, and how does it relate to precision and recall?
The F1 score is a metric that provides a balance between precision and recall. It is calculated as the harmonic mean of precision and recall, meaning it seeks to find the balance between the two metrics. The F1 score is particularly useful when there’s an uneven class distribution, as it’s less biased towards the majority class, unlike accuracy.