Large Language Models (LLMs) are a rapidly evolving field of artificial intelligence that has the potential to revolutionize the way we interact with technology. However, with great power comes great responsibility. The security and safety issues that developers and security teams must consider when building applications leveraging LLMs are numerous and complex. In this article, we provide a comprehensive overview of the recent developments in LLM research and highlight the best LLM language models available today.
Background of LLMs
LLMs are language models that can approximate human-level performance on certain evaluation benchmarks. They are primarily attributed to deep learning techniques, advancements in neural architectures like transformers, increased computational capabilities, and the accessibility of training data extracted from the internet.
LLMs, particularly pre-trained language models (PLM), have shown tremendous generalization abilities for text understanding and generation tasks while trained in a self-supervised setting on a large corpus of text. Large Language Models (LLMs) use diverse raw text to learn and generate outputs. They are capable of generating human-like text, answering questions, and even writing code. LLMs are trained on massive amounts of data, which makes them incredibly powerful but also poses significant security and safety risks.
LLMs Overview, Architectures, and Training Pipelines and Strategies
LLMs can be broadly classified into two categories: autoregressive models and autoencoding models.
- Autoregressive models generate text by predicting the next word in a sequence given the previous words.
- Autoencoding models generate text by reconstructing the input text from a compressed representation.
The most popular LLM architectures include GPT-3, T5, and BERT. These models have different strengths and weaknesses, and the choice of model depends on the specific task at hand.
Best Programming Languages For Robotics
LLM Training and Evaluation Benchmarks
LLMs are typically evaluated on a range of benchmarks, including language modeling, question answering, and text classification. The most popular benchmarks include the General Language Understanding Evaluation (GLUE) benchmark, the SuperGLUE benchmark, and the Stanford Question Answering Dataset (SQuAD). These benchmarks provide a standardized way to evaluate the performance of LLMs and compare them to other models.
Best LLM Language Models
LLMs are a fascinating result of recent advancements in artificial intelligence technology. These models are trained on enormous amounts of text data, enabling them to produce coherent and relevant text on various topics. They have the potential to transform communication and writing in fields such as business, education, and healthcare.
Based on the recent developments in LLM research and the evaluation benchmarks, we have identified the best LLM language models available today. These models include:
BERT
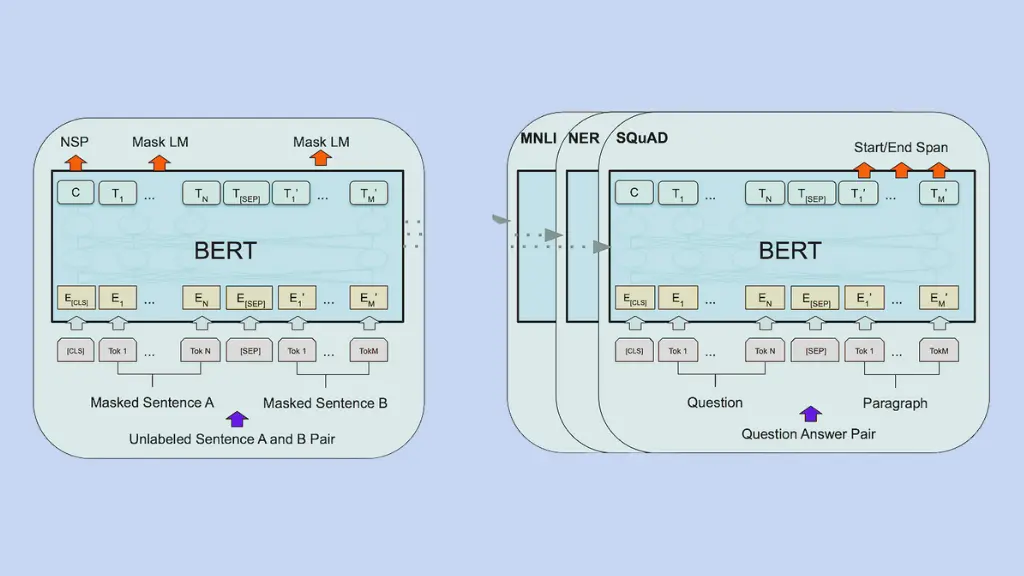
BERT (Bidirectional Encoder Representations from Transformers) is a popular LLM that excels at understanding the context of words and sentences. BERT is an autoencoding LLM developed by Google. It has 340 million parameters and has demonstrated state-of-the-art performance on a range of NLP tasks, including text classification and question answering. It is valuable for applications such as search engines and chatbots. By understanding the context of sentences, BERT can provide more accurate and relevant search results, and it helps chatbots produce more natural and human-like responses.
GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is another popular LLM that generates highly accurate and convincing text. GPT-3 is a state-of-the-art autoregressive LLM developed by OpenAI. It has 175 billion parameters and has demonstrated remarkable capabilities in a wide range of NLP tasks. It is suitable for applications such as generating conversational responses or writing articles. GPT-3 has been trained on a massive amount of data, making it one of the most powerful LLMs available today.
T5
T5 (Text-to-Text Transfer Transformer) is a versatile LLM that can perform a wide range of natural language processing tasks. T5 is an autoencoding LLM developed by Google. It has 11 billion parameters and has shown impressive performance on a range of NLP tasks, including language translation and question-answering. T5 has been trained on a diverse set of tasks, making it one of the most flexible LLMs available today.
RoBERTa (Robustly Optimized BERT Pretraining Approach)
RoBERTa is a variant of BERT that has been optimized for performance on a wide range of language tasks. RoBERTa is an autoencoding LLM developed by Facebook. It has 355 million parameters and has shown impressive performance on a range of NLP tasks, including language modeling and text classification. It has been shown to outperform BERT on several benchmarks, including the GLUE benchmark for natural language understanding.
GShard
GShard is an autoregressive LLM developed by Google that has recently gained attention in the NLP community. It has a massive 600 billion parameters, making it the largest LLM to date. GShard is designed to be highly scalable and can be trained on a distributed system with thousands of GPUs.
GShard has demonstrated remarkable capabilities in a wide range of NLP tasks, including language modeling, text classification, and question answering. It has achieved state-of-the-art performance on several benchmarks, including the SuperGLUE benchmark and the LAMBADA language modeling benchmark.
Conclusion
LLMs have revolutionized the field of natural language processing, allowing for the development of advanced applications such as chatbots and language translation. Recent research has identified several LLM models that stand out as the best in terms of performance and capabilities, including GPT-3, T5, BERT, and RoBERTa. As the field of NLP continues to evolve, it is likely that we will see even more advanced LLMs being developed and tested.