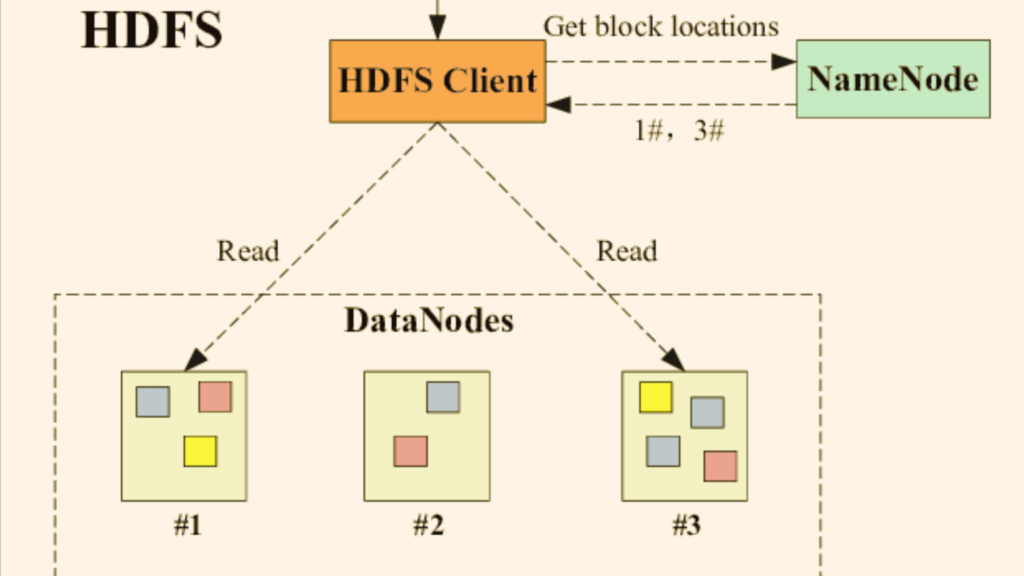
HDFS is a distributed file system designed to manage large data sets spanning multiple nodes. It is a key component of the Apache Hadoop ecosystem. HDFS provides high-throughput access to application data and is designed to handle failures gracefully.
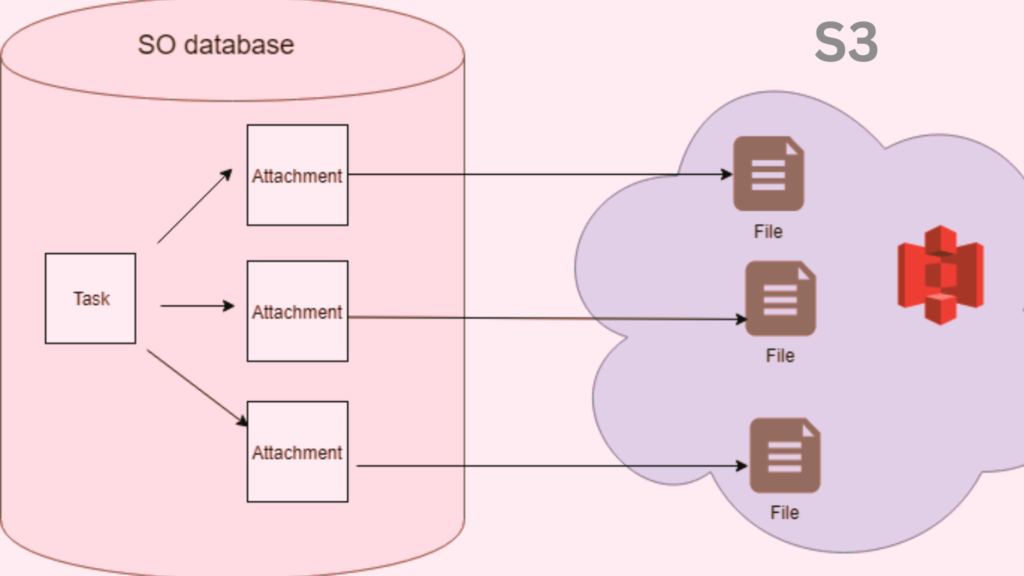
On the other hand, S3, provided by Amazon Web Services (AWS), is an object storage service. It offers industry-leading scalability, data availability, security, and performance. Thus, it enables customers to store and protect any amount of data for a range of use cases.
Is HDFS Faster Than S3?
A commonly asked question is: “Is HDFS faster than S3?”
The answer, like many things in the big data world, is: it depends. HDFS, being a distributed file system, is designed to provide high-throughput access to data. Especially, when the data and the compute nodes are on the same cluster. This proximity can provide faster data access times.
Conversely, S3, being an object store, may experience latency due to the separation of storage and compute resources. However, with recent advancements in AWS technologies, this latency has been minimized.
Can We Replace HDFS with S3?
Another question often posed is, “Can we replace HDFS with S3?”
The answer primarily hinges on your specific use case. S3 can be a suitable HDFS alternative for storing large amounts of data. It becomes more suitable when used in conjunction with other AWS services. It provides durability, ease of use, and excellent scalability, which might be beneficial in various scenarios.
However, in cases where data locality is crucial HDFS might still be the better option. For instance, running iterative algorithms on a Hadoop cluster. Additionally, HDFS allows for more straightforward data replication strategies, which is essential in disaster recovery scenarios.
Is HDFS an Object Store?
Now let’s tackle the question, “Is HDFS an object store?”
In short, no, it isn’t. HDFS is a block storage system that splits data into multiple blocks. It then distributes them across the nodes in a cluster. Unlike object stores like S3, which handle data as objects, HDFS stores data in a filesystem hierarchy. That’s why it is considered ideal for handling large files.
Can S3 be Used for Big Data?
“Can S3 be used for big data?” is another query we encounter. The answer is a resounding yes.
Amazon S3 is built to store and retrieve any amount of data at any time, from anywhere. Its durability and availability make it a compelling choice for big data workloads. Furthermore, it offers a wide array of integrations with big data frameworks like Apache Spark and Hadoop.
Is S3 an Object Store?
The answer to “Is S3 an object store?” is yes.
Amazon S3 is designed to store and retrieve any amount of data at any time. It treats data as objects, and these objects are stored in buckets. Each object contains both data and metadata and is identified by a unique, user-assigned key.
Is HDFS a Block Storage?
When we question, “Is HDFS a block storage?” the answer is yes.
HDFS splits large data sets into smaller blocks, usually of size 64MB or 128MB. It then distributes these across multiple nodes in a Hadoop cluster. This design allows for faster processing of large data sets as multiple nodes can process different blocks concurrently.
Electric Car Efficiency vs Gas: A Comprehensive Comparison
HDFS vs S3: The Final Verdict
When comparing HDFS vs S3, it’s crucial to understand that each storage system has its strengths and weaknesses. They both are designed for different scenarios and different purposes. HDFS shines in environments where data locality and replication are key. Whereas S3 stands out for its scalability, durability, and integration with other AWS services.
Lastly, addressing the question “Is S3 HDFS?” it is important to note that S3 and HDFS are two dihttps://jonascleveland.com/electric-car-efficiency-vs-gas/stinct storage systems. And of course, each has its unique attributes and uses. There is, however, an HDFS-S3 connector available to bridge these technologies. It provides the ability to leverage the benefits of both systems in a unified big data solution.
Conclusion
whether you choose HDFS or S3, it largely depends on your specific use case. Both offer unique benefits, and understanding these will help guide you in your big data journey. Always consider factors such as data volume, required processing speed, cost, and specific workload requirements before making a choice between HDFS and S3.
What is the main difference between HDFS and S3?
Can we replace HDFS with S3 in a big data infrastructure?
Is HDFS faster than S3?
What is an HDFS-S3 connector?
Is HDFS an object store?
Is S3 an object store?
Can S3 be used for big data?
Is HDFS a block storage?
References
- https://d1.awsstatic.com/events/Summits/reinvent2022/STG333_Migrate-your-on-premises-Hadoop-data-lake-to-Amazon-S3-using-AWS-DataSync.pdf
- https://min.io/resources/docs/MinIO-vs-HDFS-MapReduce-performance-comparison.pdf
- https://www.diva-portal.org/smash/get/diva2:1532694/FULLTEXT01.pdf
- https://ieeexplore.ieee.org/document/9465594